This article is part of our Academy Course titled CouchDB – Database for the Web.
This is a hands-on course on CouchDB. You will learn how to install and configure CouchDB and how to perform common operations with it. Additionally, you will build an example application from scratch and then finish the course with more advanced topics like scaling, replication and load balancing. Check it out here!

Table Of Contents
1. Introduction
As we saw in our introductory lesson, Apache CouchDB is an open source NoSQL database that uses JSON to store data, JavaScript as its query language and HTTP for an API. In CouchDB, each database is actually a collection of documents. Each document maintains its own data and a self-contained schema. An application may access multiple databases on different servers and Document metadata contain revision information in order to make merging possible in case the databases get disconnected.
In CouchDB, all operations have a unique URI that gets exposed via HTTP. The REST APIs use the typical HTTP methods POST, GET, PUT and DELETE for the four basic CRUD (Create, Read, Update, Delete) operations on all resources. Finally, Futon is CouchDB’s web-based administration console. Let’s see more details for those components.
2. Futon
Futon will can be accessed by a browser via the following address: http://localhost:5984/_utils/
The main overview page provides a list of the databases and provides the interface for querying the database and creating and updating documents.
The main sections in Futon are:
- Configuration: An interface into the configuration of Wer CouchDB installation. The interface allows us to edit the different configurable parameters.
- Replicator: An interface to the replication system, enabling us to initiate replication between local and remote databases.
- Status: Displays a list of the running background tasks on the server. Background tasks include view index building, compaction and replication. The Status page is an interface to the Active Tasks API call.
- Verify Installation: The Verify Installation allows us to check whether all of the components of CouchDB installation are correctly installed.
- Test Suite: The Test Suite section allows us to run the built-in test suite. This executes a number of test routines entirely within browser to test the API and functionality of CouchDB installation.
2.1 Managing Databases and Documents
We can manage databases and documents within Futon using the main Overview section of the Futon interface.
To create a new database, click the Create Database Ellipsis button. We will be prompted for the database name, as shown in the figure below.
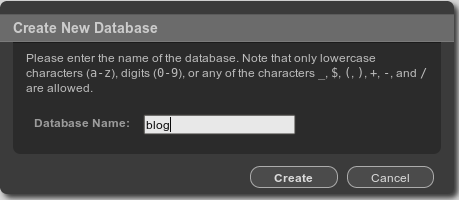
Type the database name (i.e. ‘blog’ here) in the textbox that we want to create.
Once we have created the database (or selected an existing one), we will be shown a list of the current documents. If we create a new document, or select an existing document, we will be presented with the edit document display.
Editing documents within Futon requires selecting the document and then editing (and setting) the fields for the document individually before saving the document back into the database.
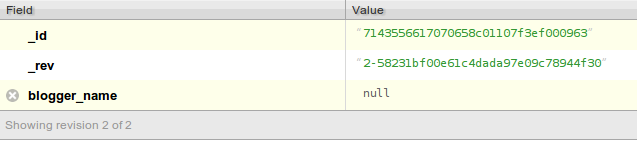
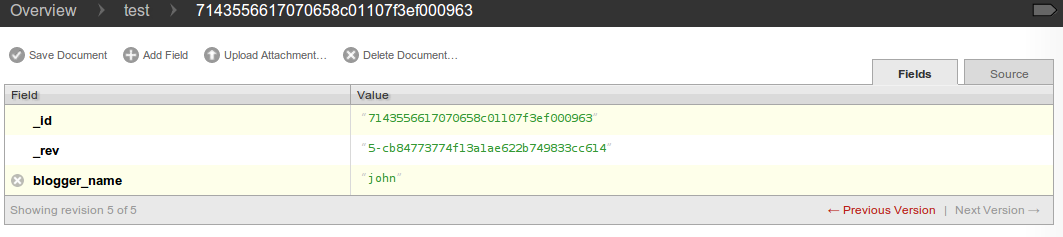
For example, the figure below shows the editor for a single document, a newly created document with a single ID, the document _id field (click on the image to show in full size).

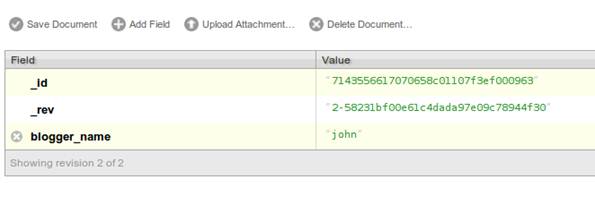
To add a field to the document:
- Click Add Field.
- In the fieldname box, enter the name of the field. For example, “blogger_name”.
- Click the green tick next to the field name to confirm the field name change.
- Double-click the corresponding Value cell.
- Enter a company name, for example “john”.
- Click the green tick next to the field value to confirm the field value.
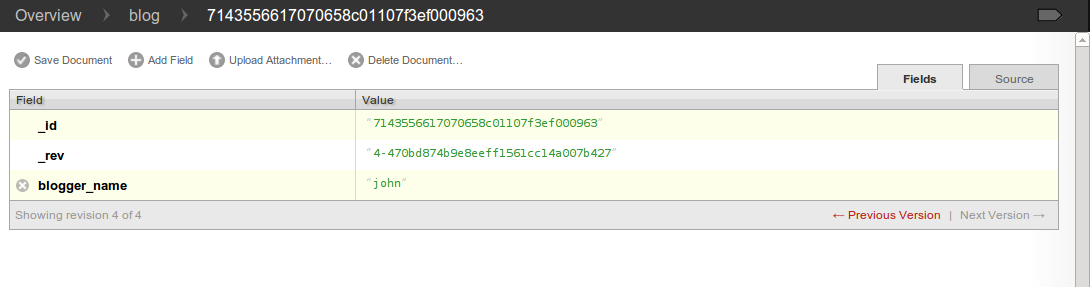
- We must explicitly save the document by clicking the Save Document button at the top of the page. This will save the document, and then display the new document with the saved revision information (the _rev field). (Click on image to show in full size)
2.2 Configuring Replication
When we click the Replicator option within the Tools menu we are presented with the Replicator screen. This allows us to start replication between two databases by filling in or select the appropriate options within the form provided.
For example, let’s say we have another database ‘test’. So the list of databases are the following:
Now we are going to replicate database from ‘blog’ to ‘test’.
To do that, click on the ‘Replicator’ on the right side panel.
To start the replication process, either select the local database or enter a remote database name into the corresponding areas of the form. The replication occurs from the database on the left to the database on the right.
If we are specifying a remote database name, we must specify the full URL of the remote database (including the host, port number and database name). If the remote instance requires authentication, we can specify the username and password as part of the URL, for example http://username:pass@remotehost:5984/blog. (Click on image to show in full size)

To enable continuous replication, click the Continuous checkbox. Click on the ‘Replicate’ button.
The replication process should start and will continue in the background. If the replication process takes a long time, we can monitor the status of the replication using the Status option under the Tools menu.
Once the replication has been completed, the page will show the information using the CouchDB API.
The result will be shown like in the following image (Click on image to show in full size):

If we now open the ‘test’ database, we will find an exact replica of the ‘blog’ database:
3. CRUD Operations
Next, we will have a quick look at CouchDB’s bare-bones Application Programming Interface (API) by using the command-line utility “curl”. It gives us control over raw HTTP requests and we can see exactly what is going on the database.
Make sure CouchDB is still running and then from the command line execute the following:
curl http://127.0.0.1:5984/
This issues a GET request to the newly installed CouchDB instance. The reply should look something like:
{"couchdb":"Welcome","version":"1.0.1"}Next, we can get a list of the existing databases:
curl -X GET http://127.0.0.1:5984/_all_dbs
Note that we added the “_all_dbs” string to the initial request.. The response should look like:
["_users","blog","test"]
It is showing our 2 databases named blog and test which were created earlier via the Futon UI.
Let’s create another database, using the API this time:
curl -X PUT http://127.0.0.1:5984/shopcart
Executing this, the CouchDB will reply with:
{"ok":true}Retrieving the list of databases again shows some useful results:
curl -X GET http://127.0.0.1:5984/_all_dbs
The output shows:
["_users","blog","shopcart","test"]
Let’s create another database with the same database name:
curl -X PUT http://127.0.0.1:5984/shopcart
CouchDB will reply with:
{"error":"file_exists","reason":"The database could not be created, the file already exists."}We already have a database with that name, so CouchDB will respond with an error. Let’s try again with a different database name:
curl -X PUT http://127.0.0.1:5984/bookstore
CouchDB will reply with:
{"ok":true}Retrieving the list of databases yet again shows some useful results:
curl -X GET http://127.0.0.1:5984/_all_dbs
CouchDB will respond with:
["bookstore","_users","blog","shopcart","test"]
To round things off, let’s delete the second database:
curl -X DELETE http://127.0.0.1:5984/bookstore
CouchDB will reply with:
{"ok":true}The list of databases is now the same as it was before:
curl -X GET http://127.0.0.1:5984/_all_dbs
CouchDB will respond with:
["_users","blog","shopcart","test"]
Everything is done using the standard HTTP methods, GET, PUT, POST, and DELETE with the appropriate URI.
3.1 Documents
Documents are CouchDB’s central data structure. To better understand and use CouchDB, we need to think in terms of documents. In this chapter we will walk though the lifecycle of designing and saving a document. We’ll follow up by reading documents and aggregating and querying them with views.
Documents are self-contained units of data. The data is usually made up of small native types such as integers and strings. Documents are the first level of abstraction over these native types. They provide some structure and logically group the primitive data. The height of a person might be encoded as an integer (176), but this integer is usually part of a larger structure that contains a label (“height”: 176) and related data ({“name”:”Chris”, “height”: 176}).
How many data items can be put into the documents depends on the application and a bit on how we want to use views. Generally, a document corresponds to an object instance in the programming language.
Documents differ subtly from garden-variety objects in that they usually have authors and CRUD operations (create, read, update, delete). Document-based software (like the word processors and spreadsheets) build their storage model around saving documents so that authors get back what they created.
Validation functions are available so that we don’t have to worry about bad data causing errors in our system. Often in document-based software, the client application edits and manipulates the data, saving it back.
Let’s suppose a user can comment on the item (“lovely book”); we have the option to store the comments as an array, on the item document. This makes it trivial to find the item’s comments, but, as they say, “it doesn’t scale.” A popular item could have tens of comments, or even hundreds or more.
Instead of storing a list on the item document, in this case it may be acutally better to model comments into a collection of documents. There are patterns for accessing collections, which CouchDB makes easy. We likely want to show only 10 or 20 at a time and provide previous and next links. By handling comments as individual entities, we can group them with views. A group could be the entire collection or slices of 10 or 20, sorted by the item they apply to so that it’s easy to grab the set we need.
Everything that will be handled separately in the application should be broken up into documents. Items are single, and comments are single, but we don’t need to break them into smaller pieces. Views provide a convenient way to group our documents in meaningful ways.
4. Common HTTP operations
We start out by revisiting the basic operations we ran in the last chapter, looking behind the scenes. We will also discover what Futon runs in the background in order to give us the nice features we saw earlier.
While explaining the API bits and pieces, we sometimes need to take a larger detour to explain the reasoning for a particular request. This is a good opportunity for us to tell why CouchDB works the way it does.
The API can be subdivided into the following sections. We’ll explore them individually:
- Server
- Databases
- Documents
- Replication
- Server
This one is basic and simple. It can serve as a sanity check to see if CouchDB is running at all. It can also act as a safety guard for libraries that require a certain version of CouchDB. We’re using the curl utility again:
curl http://127.0.0.1:5984/
CouchDB replies, all excited to get going:
{"couchdb":"Welcome","version":"1.0.1"}We get back a JSON string, which, if parsed into a native object or data structure of our programming language, gives us access to the welcome string and version information.
This is not terribly useful, but it illustrates nicely the way CouchDB behaves. We send an HTTP request and we receive a JSON string in the HTTP response as a result.
4.1 Databases
Strictly speaking, CouchDB is a database management system (DMS). That means it can hold multiple databases. A database is a bucket that holds “related data.” We’ll explore later what that means in detail. In practice, the terminology is overlapping—often people refer to a DMS as “a database” and also a database within the DMS as “a database.” We might follow that slight oddity, so don’t get confused by it. In general, it should be clear from the context if we are talking about the whole of CouchDB or a single database within CouchDB.
Now let’s make one! Note that we’re now using the -X option again to tell curl to send a PUT request instead of the default GET request:
curl -X PUT http://127.0.0.1:5984/student
CouchDB replies:
{"ok":true}That’s it. We created a database and CouchDB told us that all went well. What happens if we try to create a database that already exists? Let’s try to create that database again:
curl -X PUT http://127.0.0.1:5984/student
CouchDB replies:
{"error":"file_exists","reason":"The database could not be created, the file already exists."}We get back an error. This is pretty convenient. CouchDB stores each database in a single file.
Let’s create another database, this time with curl’s -v (for “verbose”) option. The verbose option tells curl to show us not only the essentials—the HTTP response body—but all the underlying request and response details:
curl -vX PUT http://127.0.0.1:5984/student-backup
Curl elaborates:
* About to connect() to 127.0.0.1 port 5984 (#0)
* Trying 127.0.0.1... connected
> PUT /student-backup HTTP/1.1
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Host: 127.0.0.1:5984
> Accept: */*
>
< HTTP/1.1 201 Created
< Server: CouchDB/1.0.1 (Erlang OTP/R14B)
< Location: http://127.0.0.1:5984/student-backup
< Date: Sat, 15 Feb 2014 17:50:51 GMT
< Content-Type: text/plain;charset=utf-8
< Content-Length: 12
< Cache-Control: must-revalidate
< {"ok":true} * Connection #0 to host 127.0.0.1 left intact * Closing connection #0Let’s step through this line by line in order to understand what’s going on and find out what’s important. Once we’ve seen this output a few times, we’ll be able to spot the important bits more easily.
* About to connect() to 127.0.0.1 port 5984 (#0)
This is curl telling us that it is going to establish a TCP connection to the CouchDB server we specified in our request URI. Not at all important, except when debugging networking issues.
* Trying 127.0.0.1... connected * Connected to 127.0.0.1 (127.0.0.1) port 5984 (#0)
Curl tells us it successfully connected to CouchDB. Again, not important if there is no problem with the network. The following lines are prefixed with > and < characters. > means the line was sent to CouchDB verbatim (without the actual >). < means the line was sent back to curl by CouchDB.
> PUT /student-backup HTTP/1.1
This initiates an HTTP request. Its method is PUT, the URI is /student-backup, and the HTTP version is HTTP/1.1. There is also HTTP/1.0, which is simpler in some cases, but for all practical reasons We should be using HTTP/1.1.
Next, we see a number of request headers. These are used to provide additional details about the request to CouchDB.
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
The User-Agent header tells CouchDB which piece of client software is doing the HTTP request. It’s the curl program. This header is often useful in web development when there are known errors in client implementations that a server might want to prepare the response for. It also helps to determine which platform a user is on. This information can be used for technical and statistical reasons. For CouchDB, the User-Agent header is not very relevant.
> Host: 127.0.0.1:5984
The Host header is required by HTTP 1.1. It tells the server the hostname that came with the request.
> Accept: */*
The Accept header tells CouchDB that curl accepts any media type. We’ll look into why this is useful a little later.
>
An empty line denotes that the request headers are now finished and the rest of the request contains data we’re sending to the server. In this case, we’re not sending any data, so the rest of the curl output is dedicated to the HTTP response.
< HTTP/1.1 201 Created
The first line of CouchDB’s HTTP response includes the HTTP version information (again, to acknowledge that the requested version could be processed), an HTTP status code, and a status code message. Different requests trigger different response codes. There’s a whole range of them telling the client (curl in our case) what effect the request had on the server. Or, if an error occurred, what kind of error.
RFC 2616 (the HTTP 1.1 specification) defines clear behavior for response codes. CouchDB fully follows the RFC. The 201 Created status code tells the client that the resource the request was made against was successfully created. No surprise here, but if we remember that we got an error message when we tried to create this database twice, we now know that this response could include a different response code.
Acting upon responses based on response codes is a common practice. For example, all response codes of 400 (or greater than that) inform us that some error occurred. If we want to shortcut the logic and immediately deal with the error, we could just check a >= 400 response code.
< Server: CouchDB/0.10.1 (Erlang OTP/R13B)
The Server header is good for diagnostics. It tells us which CouchDB version and which underlying Erlang version we are talking to. In general, we can ignore this header, but it is good to know it’s there if We need it.
< Date: Sun, 05 Jul 2009 22:48:28 GMT
The Date header tells the time of the server. Since client and server time are not necessarily synchronized, this header is purely informational. We shouldn’t build any critical application logic on top of this!
< Content-Type: text/plain;charset=utf-8
The Content-Type header tells which MIME type the HTTP response body uses and what encoding is used for it. We already know that CouchDB returns JSON strings. The appropriate Content-Type header is application/json. Why do we see text/plain? This is where pragmatism wins over purity. Sending an application/json Content-Type header will make a browser offer the returned JSON for download instead of just displaying it. Since it is extremely useful to be able to test CouchDB from a browser, CouchDB sends a text/plain content type, so all browsers will display the JSON as text.
There are some extensions that make our browser JSON-aware, but they are not installed by default. For more information, look at the popular JSONView extension, available for both Firefox and Chrome.
If we send Accept: application/json in our request, CouchDB knows that we can deal with a pure JSON response with the proper Content-Type header and will use it instead of text/plain.
< Content-Length: 12
The Content-Length header simply tells us how many bytes the response body has.
< Cache-Control: must-revalidate
This Cache-Control header tells us, or any proxy server between CouchDB and us, not to cache this response.
<
This empty line tells us we’re done with the response headers and what follows now is the response body.
* Connection #0 to host 127.0.0.1 left intact * Closing connection #0
The last two lines are curl telling us that it kept the TCP connection it opened in the beginning open for a moment, but then closed it after it received the entire response.
> curl -vX DELETE http://127.0.0.1:5984/albums-backup
This deletes a CouchDB database. The request will remove the file that the database contents are stored in. We need to use this command with care, as our data will be deleted without a chance to bring it back easily if we don’t have a backup copy.
The console will look like this:
* About to connect() to 127.0.0.1 port 5984 (#0)
* Trying 127.0.0.1... connected
> DELETE /student-backup HTTP/1.1
> User-Agent: curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3
> Host: 127.0.0.1:5984
> Accept: */*
>
< HTTP/1.1 200 OK
< Server: CouchDB/1.0.1 (Erlang OTP/R14B)
< Date: Sat, 15 Feb 2014 17:53:58 GMT
< Content-Type: text/plain;charset=utf-8
< Content-Length: 12
< Cache-Control: must-revalidate
<
{"ok":true}
* Connection #0 to host 127.0.0.1 left intact
* Closing connection #0
This section went knee-deep into HTTP and set the stage for discussing the rest of the core CouchDB API. Next stop: documents.
4.2 Documents
Let’s have a closer look at our document creation requests with the curl -v flag that was helpful when we explored the database API earlier. This is also a good opportunity to create more documents that we can use in later examples.
We’ll add some more of our favorite music albums. Get a fresh UUID from the /_uuids resource. If we don’t remember how that works, w can look it up a few pages back.
curl -vX PUT http://127.0.0.1:5984/albums/70b50bfa0a4b3aed1f8aff9e92dc16a0 -d '{"title":"Blackened Sky","artist":"Biffy Clyro","year":2002}'Now with the -v option, CouchDB’s reply (with only the important bits shown) looks like this:
> PUT /albums/70b50bfa0a4b3aed1f8aff9e92dc16a0 HTTP/1.1
>
< HTTP/1.1 201 Created
< Location: http://127.0.0.1:5984/albums/70b50bfa0a4b3aed1f8aff9e92dc16a0
< Etag: "1-2248288203"
<
{"ok":true,"id":"70b50bfa0a4b3aed1f8aff9e92dc16a0","rev":"1-2248288203"}
We’re getting back the 201 Created HTTP status code in the response headers, as we saw earlier when we created a database. The Location header gives us a full URL to our newly created document and there’s a new header. An Etag in HTTP-speak identifies a specific version of a resource. In this case, it identifies a specific version (the first one) of our new document. An Etag is the same as a CouchDB document revision number, and it shouldn’t come as a surprise that CouchDB uses revision numbers for Etags. Etags are useful for caching infrastructures.
4.3 Attachments
CouchDB documents can have attachments just like an email message can have attachments. An attachment is identified by a name and includes its MIME type (or Content-Type) and the number of bytes the attachment contains. Attachments can consist of any type of data. It is easier to think about attachments as files attached to a document. These files can be text, images, Word documents, music, or movie files. Let’s make one.
Attachments get their own URL where we can upload data. Let’s suppose we want to add the album artwork to the 6e1295ed6c29495e54cc05947f18c8af document (“There is Nothing Left to Lose”), and let’s also say the artwork is in a file artwork.jpg in the current directory:
> curl -vX PUT http://127.0.0.1:5984/albums/6e1295ed6c29495e54cc05947f18c8af/artwork.jpg?rev=2-2739352689 --data-binary @artwork.jpg -H "Content-Type: image/jpg"
The –data-binary @ option tells curl to read a file’s contents into the HTTP request body. We’re using the -H option to tell CouchDB that we’re uploading a JPEG file. CouchDB will keep this information around and will send the appropriate header when requesting this attachment; in case of an image like this, a browser will render the image instead of offering the data for download. This will come in handy later. Note that we need to provide the current revision number of the document we’re attaching the artwork to, just as if we would update the document.
If we request the document again, we will see a new member:
curl http://127.0.0.1:5984/albums/6e1295ed6c29495e54cc05947f18c8af
CouchDB replies:
{"_id":"6e1295ed6c29495e54cc05947f18c8af","_rev":"3-131533518","title": "There is Nothing Left to Lose","artist":"Foo Fighters","year":"1997","_attachments":{"artwork.jpg":{"stub":true,"content_type":"image/jpg","length":52450}}}_attachments is a list of keys and values where the values are JSON objects containing the attachment metadata. stub=true tells us that this entry is just the metadata. If we use the ?attachments=true HTTP option when requesting this document, we’d get a Base64-encoded string containing the attachment data.
We’ll have a look at more document request options later as we explore more features of CouchDB, such as replication, which is the next topic.
4.4 Replication
CouchDB replication is a mechanism to synchronize databases. Much like rsync synchronizes two directories locally or over a network, replication synchronizes two databases locally or remotely.
Using a simple POST request, we tell CouchDB the source and the target of a replication and CouchDB will figure out which documents and new document revisions exist on the source DB and they are not yet on the target DB, and will proceed to move the missing documents and revisions over.
First, we’ll create a target database. Note that CouchDB won’t automatically create a target database and will return a replication failure if the target doesn’t exist:
curl -X PUT http://127.0.0.1:5984/albums-replica
Now we can use the database albums-replica as a replication target:
curl -vX POST http://127.0.0.1:5984/_replicate -d '{"source":"albums","target":"albums-replica"}' -H "Content-Type: application/json"CouchDB replies (this time we formatted the output so We can read it more easily):
{
"history": [
{
"start_last_seq": 0,
"missing_found": 2,
"docs_read": 2,
"end_last_seq": 5,
"missing_checked": 2,
"docs_written": 2,
"doc_write_failures": 0,
"end_time": "Sat, 11 Jul 2009 17:36:21 GMT",
"start_time": "Sat, 11 Jul 2009 17:36:20 GMT"
}
],
"source_last_seq": 5,
"session_id": "924e75e914392343de89c99d29d06671",
"ok": true
}CouchDB maintains a session history of replications. The response for a replication request contains the history entry for this replication session. It is also worth noting that the request for replication will stay open until replication closes. If we have a lot of documents, it’ll take a while until they are all replicated and we won’t get back the replication response until all documents are replicated. It is important to note that replication replicates the database only as it was at the point in time when replication was started. So, any additions, modifications, or deletions subsequent to the start of replication will not be replicated.
We’ll punt on the details again: the “ok”: true at the end tells us all went well. If we have a look at the albums-replica database, we should see all the documents that we created in the albums database.
In CouchDB terms, we created a local copy of a database. This is useful for backups or to keep snapshots of a specific state of data around for later.
There are more types of replication useful in other situations. The source and target members of our replication request are actually links (like in HTML) and so far we’ve seen links relative to the server we’re working on (hence local). We can also specify a remote database as the target:
curl -vX POST http://127.0.0.1:5984/_replicate -d '{"source":"albums","target":"http://example.org:5984/albums-replica"}' -H "Content-Type: application/json"Using a local source and a remote target database is called push replication. We’re pushing changes to a remote server.
We can also use a remote source and a local target to do a pull replication. This is great for getting the latest changes from a server that is used by others:
curl -vX POST http://127.0.0.1:5984/_replicate -d '{"source":"http://example.org:5984/albums-replica","target":"albums"}' -H "Content-Type: application/json"Finally, we can run remote replication, which is mostly useful for management operations:
curl -vX POST http://127.0.0.1:5984/_replicate -d '{"source":"http://example.org:5984/albums","target":"http://example.org:5984/albums-replica"}' -H "Content-Type: application/json"5. JSON
CouchDB uses JavaScript Object Notation (JSON) for data storage. JSON is a lightweight format based on a subset of JavaScript syntax. One of the best bits about JSON is that it’s easy to read and write by hand, much more so than something like XML. We can parse it naturally with JavaScript because it shares part of the same syntax. This really comes in handy when we’re building dynamic web applications and we want to fetch some data from the server.
Here’s a sample JSON document:
{
"Subject": "I like Plankton",
"Author": "Rusty",
"PostedDate": "2006-08-15T17:30:12-04:00",
"Tags": [
"plankton",
"baseball",
"decisions"
],
"Body": "I decided today that I don't like baseball. I like plankton."
}We can see that the general structure is based around key/value pairs and lists of things.
5.1 Data Types
JSON has a number of basic data types We can use. We’ll cover them all here.
5.2 Numbers
We can have positive integers: “Count”: 253
Or negative integers: “Score”: -19
Or floating-point numbers: “Area”: 456.31
Or scientific notation: “Density”: 5.6e+24
5.3 Strings
We can use strings for values:
"Author": "Rusty"
We have to escape some special characters, like tabs or newlines:
"poem": "May I compare thee to some\\n\\tsalty plankton."
The JSON site has details on what needs to be escaped.
5.4 Booleans
We can have boolean true values:
"Draft": true
Or boolean false values:
"Draft": false
Arrays
An array is a list of values:
"Tags": ["plankton", "baseball", "decisions"]
An array can contain any other data type, including arrays:
"Context": ["dog", [1, true], {"Location": "puddle"}]Objects
An object is a list of key/value pairs:
{"Subject": "I like Plankton", "Author": "Rusty"}Nulls
We can have null values:
"Surname": null
6. Documents
Documents are CouchDB’s central data structure. The idea behind a document is, unsurprisingly, that of a real-world document – a sheet of paper such as an invoice, a recipe, or a business card. We have already learned that CouchDB uses the JSON format to store documents. Let’s see how this storing works at the lowest level.
Each document in CouchDB has an ID. This ID is unique per database. We are free to choose any string to be the ID, but for best results we recommend a UUID (or GUID), i.e., a Universally (or Globally) Unique IDentifier. UUIDs are random numbers that have such a low collision probability. We can make thousands of UUIDs per minute for millions of years without ever creating a duplicate. This is a great way to ensure two independent people cannot create two different documents with the same ID. Why should we care what somebody else is doing? For one, somebody else could be at a later time or on a different computer; secondly, CouchDB replication let’s us share documents with others and using UUIDs ensures that it all works. But more on that later; let’s make some documents:
curl -X PUT http://127.0.0.1:5984/shopcart/6e1295ed6c29495e54cc05947f18c8af -d '{"title":"There is Nothing Left to Lose","artist":"Foo Fighters"}'CouchDB replies:
{"ok":true,"id":"6e1295ed6c29495e54cc05947f18c8af","rev":"1-2902191555"}The curl command appears complex, but let’s break it down. First, -X PUT tells curl to make a PUT request. It is followed by the URL that specifies Wer CouchDB IP address and port. The resource part of the URL /albums/6e1295ed6c29495e54cc05947f18c8af specifies the location of a document inside our albums database. The wild collection of numbers and characters is a UUID. This UUID is Wer document’s ID. Finally, the -d flag tells curl to use the following string as the body for the PUT request. The string is a simple JSON structure including title and artist attributes with their respective values.
A CouchDB document is simply a JSON object. We can use any JSON structure with nesting. We can fetch the document’s revision information by adding ?revs_info=true to the get request.
To get a UUID, we use:
curl -X GET http://127.0.0.1:5984/_uuids
CouchDb will reply us back, like this:
{"uuids":["6e1295ed6c29495e54cc05947f18c8af"]}Here are two simple examples of documents:
{
"_id":"discussion_tables",
"_rev":"D1C946B7",
"Sunrise":true,
"Sunset":false,
"FullHours":[1,2,3,4,5,6,7,8,9,10],
"Activities": [
{"Name":"Football", "Duration":2, "DurationUnit":"Hours"},
{"Name":"Breakfast", "Duration":40, "DurationUnit":"Minutes", "Attendees":["Jan", "Damien", "Laura", "Gwendolyn", "Roseanna"]}
]
}{
"_id":"some_doc_id",
"_rev":"D1C946B7",
"Subject":"I like Plankton",
"Author":"Rusty",
"PostedDate":"2006-08-15T17:30:12-04:00",
"Tags":["plankton", "baseball", "decisions"],
"Body":"I decided today that I don't like baseball. I like plankton."
}6.1 Special Fields
Note that any top-level fields within a JSON document containing a name that starts with a _ prefix are reserved for use by CouchDB itself. Also see Reserved_words. Currently (0.10+) reserved fields are:
| Field Name | Description |
| _id | The unique identifier of the document (mandatory and immutable) |
| _rev | The current MVCC-token/revision of this document (mandatory and immutable) |
| _attachments | If the document has attachments, _attachments holds a (meta-)data structure (see section on HTTP_Document_API#Attachments) |
| _deleted | Indicates that this document has been deleted and previous revisions will be removed on next compaction run |
| _revisions | Revision history of the document |
| _revs_info | A list of revisions of the document, and their availability |
| _conflicts | Information about conflicts |
| _deleted_conflicts | Information about conflicts |
| _local_seq | Sequence number of the revision in the database (as found in the _changes feed) |
Table 1
To request a special field to be returned along with the normal fields we get when we request a document, add the desired field as a query parameter without the leading underscore in a GET request:
curl -X GET 'http://localhost:5984/my_database/my_document?conflicts=true'
This request will return a document that includes the special field ‘_conflicts’ which contains all the conflicting revisions of “my_document”.
[Exception: The query parameter for the _revisions special field is ‘revs’, not ‘revisions’.]
6.2 Document IDs
Document IDs don’t have restrictions on what characters can be used. Although it should work, it is recommended to use non-special characters for document IDs. By using special characters, we have to be aware of proper URL en-/decoding. Documents prefixed with _ are special documents:
| Document ID prefix | Description |
| _design/ | are DesignDocuments |
| _local/ | are not being replicated (local documents) and used for Replication checkpointing. |
Table 2
We can have / as part of the document ID but if We refer to a document in a URL We must always encode it as %2F. One special case is _design/ documents, those accept either / or %2F for the / after _design, although / is preferred and %2F is still needed for the rest of the DocID.
6.3 Working With Documents Over HTTP
GET
To retrieve a document, simply perform a GET operation at the document’s URL:
curl -X GET http://127.0.0.1:5984/shopcart/6e1295ed6c29495e54cc05947f18c8af
Here is the server’s response:
{"_id":"6e1295ed6c29495e54cc05947f18c8af","_rev":"1-4b39c2971c9ad54cb37e08fa02fec636","title":"There is Nothing Left to Lose","artist":"Foo Fighters"}7. Revisions
If we want to change a document in CouchDB, we don’t tell it to go and find a field in a specific document and insert a new value. Instead, we load the full document out of CouchDB, make our changes in the JSON structure (or object, when we are doing actual programming), and save the entire new revision (or version) of that document back into CouchDB. Each revision is identified by a new _rev value.
If we want to update or delete a document, CouchDB expects us to include the_rev field of the revision we wish to change. When CouchDB accepts the change, it will generate a new revision number. This mechanism ensures that, in case somebody else made a change without us knowing before we got to request the document update, CouchDB will not accept our update because we are likely to overwrite data we didn’t know that even existed. Or simplified: whoever saves a change to a document first, wins. Let’s see what happens if we don’t provide a _rev field (which is equivalent to providing a outdated value):
curl -X PUT http://127.0.0.1:5984/shopcart/6e1295ed6c29495e54cc05947f18c8af -d '{"title":"There is Nothing Left to Lose","artist":"Foo Fighters","year":"1997"}'CouchDB replies:
{"error":"conflict","reason":"Document update conflict."}If we see this, add the latest revision number of your document to the JSON structure:
curl -X PUT http://127.0.0.1:5984/shopcart/6e1295ed6c29495e54cc05947f18c8af -d '{"_rev":"1-2902191555","title":"There is Nothing Left to Lose", "artist":"Foo Fighters","year":"1997"}'Now we see why it was handy that CouchDB returned that _rev when we made the initial request. CouchDB replies:
{"ok":true,"id":"6e1295ed6c29495e54cc05947f18c8af","rev":"2-2739352689"}7.1 Accessing Previous Revisions
The above example gets the current revision. We may be able to get a specific revision by using the following syntax:
GET /somedatabase/some_doc_id?rev=946B7D1C HTTP/1.0
To find out what revisions are available for a document, we can do:
GET /somedatabase/some_doc_id?revs_info=true HTTP/1.0
This returns the current revision of the document, but with an additional _revs_info field, whose value is an array of objects, one per revision. For example:
{
"_revs_info": [
{"rev": "3-ffffff", "status": "available"},
{"rev": "2-eeeeee", "status": "missing"},
{"rev": "1-dddddd", "status": "deleted"},
]
}Here, available means the revision content is stored in the database and can still be retrieved. The other values indicate that the content of that revision is not available.
Alternatively, the _revisions field, used by the replicator, can return an array of revision IDs more efficiently. The numeric prefixes are removed, with a “start” value indicating the prefix for the first (most recent) ID:
{
"_revisions": {
"start": 3,
"ids": ["fffff", "eeeee", "ddddd"]
}
}We can fetch the bodies of multiple revisions at once using the parameter open_revs=[“rev1″,”rev2”,…], or We can fetch all leaf revisions using open_revs=all. The JSON returns an array of objects with an “ok” key pointing to the document, or a “missing” key pointing to the rev string.
[
{"missing":"1-fbd8a6da4d669ae4b909fcdb42bb2bfd"},
{"ok":{"_id":"test","_rev":"2-5bc3c6319edf62d4c624277fdd0ae191","hello":"foo"}}
]7.2 HEAD
A HEAD request returns basic information about the document, including its current revision.
HEAD /somedatabase/some_doc_id HTTP/1.0 HTTP/1.1 200 OK Etag: "946B7D1C" Date: Thu, 17 Aug 2006 05:39:28 +0000GMT Content-Type: application/json Content-Length: 256
7.3 PUT
To create new document we can either use a POST operation or a PUT operation. To create/update a named document using the PUT operation, the URL must point to the document’s location.
The following is an example HTTP PUT. It will cause the CouchDB server to generate a new revision ID and save the document with it.
PUT /somedatabase/some_doc_id HTTP/1.0
Content-Length: 245
Content-Type: application/json
{
"Subject":"I like Plankton",
"Author":"Rusty",
"PostedDate":"2006-08-15T17:30:12-04:00",
"Tags":["plankton", "baseball", "decisions"],
"Body":"I decided today that I don't like baseball. I like plankton."
}Here is the server’s response.
HTTP/1.1 201 Created
Etag: "946B7D1C"
Date: Thu, 17 Aug 2006 05:39:28 +0000GMT
Content-Type: application/json
Connection: close
{"ok": true, "id": "some_doc_id", "rev": "946B7D1C"}
To update an existing document, we also issue a PUTrequest. In this case, the JSON body must contain a _rev property, which lets CouchDB know which revision the edits are based on. If the revision of the document currently stored in the database doesn’t match, then a 409 conflict error is returned.
If the revision number does match what’s in the database, a new revision number is generated and returned to the client.
For example:
PUT /somedatabase/some_doc_id HTTP/1.0
Content-Length: 245
Content-Type: application/json
{
"_id":"some_doc_id",
"_rev":"946B7D1C",
"Subject":"I like Plankton",
"Author":"Rusty",
"PostedDate":"2006-08-15T17:30:12-04:00",
"Tags":["plankton", "baseball", "decisions"],
"Body":"I decided today that I don't like baseball. I like plankton."
}Here is the server’s response if what is stored in the database is a revision 946B7D1C of document some_doc_id.
HTTP/1.1 201 Created
Etag: "2774761002"
Date: Thu, 17 Aug 2006 05:39:28 +0000GMT
Content-Type: application/json
Connection: close
{"ok":true, "id":"some_doc_id", "rev":"2774761002"}And here is the server’s response if there is an update conflict (what is currently stored in the database is not revision 946B7D1C of document some_doc_id).
HTTP/1.1 409 Conflict
Date: Thu, 17 Aug 2006 05:39:28 +0000GMT
Content-Length: 33
Connection: close
{"error":"conflict","reason":"Document update conflict."}There is a query option batch=okwhich can be used to achieve higher throughput at the cost of lower guarantees. When a PUT(or a document POSTas described below) is sent using this option, it is not immediately written to disk. Instead it is stored in memory on a per-user basis for a second or so (or the number of docs in memory reaches a certain point). After the threshold has passed, the docs are committed to disk. Instead of waiting for the doc to be written to disk before responding, CouchDB sends an HTTP 202 Accepted response immediately.
batch=ok is not suitable for crucial data, but it ideal for applications like logging which can accept the risk that a small proportion of updates could be lost due to a crash. Docs in the batch can also be flushed manually using the _ensure_full_commit API.
7.4 POST
The POSToperation can be used to create a new document with a server generated DocID. To do so, the URL must point to the database’s location. To create a named document, use the PUTmethod instead.
It is recommended that we avoid POSTwhen possible, because proxies and other network intermediaries will occasionally resend POSTrequests, which can result in duplicate document creation. If our client software is not capable of guaranteeing uniqueness of generated UUIDs, use a GETto /_uuids?count=100to retrieve a list of document IDs for future PUT requests. Please note that the /_uuids-call does not check for existing document ids; collision-detection happens when We are trying to save a document.
The following is an example HTTP POST. It will cause the CouchDB server to generate a new DocID and revision ID and save the document with it.
POST /somedatabase/ HTTP/1.0
Content-Length: 245
Content-Type: application/json
{
"Subject":"I like Plankton",
"Author":"Rusty",
"PostedDate":"2006-08-15T17:30:12-04:00",
"Tags":["plankton", "baseball", "decisions"],
"Body":"I decided today that I don't like baseball. I like plankton."
}
Here is the server’s response:
HTTP/1.1 201 Created
Date: Thu, 17 Aug 2006 05:39:28 +0000GMT
Content-Type: application/json
Connection: close
{"ok":true, "id":"123BAC", "rev":"946B7D1C"}As of 0.11 CouchDB supports handling of multipart/form-data encoded updates. This is used by Futon and not considered a public API. All such requests must contain a valid Referer header.
7.5 DELETE
To delete a document, perform a DELETE operation at the document’s location, passing the rev parameter with the document’s current revision. If successful, it will return the revision id for the deletion stub.
DELETE /somedatabase/some_doc?rev=1582603387 HTTP/1.0
As an alternative we can submit the rev parameter with the etag header field If-Match.
DELETE /somedatabase/some_doc HTTP/1.0 If-Match: "1582603387"
And the response:
HTTP/1.1 200 OK
Etag: "2839830636"
Date: Thu, 17 Aug 2006 05:39:28 +0000GMT
Content-Type: application/json
Connection: close
{"ok":true,"rev":"2839830636"}Note: Deleted documents remain in the database forever, even after compaction, to allow eventual consistency when replicating. If we delete using the DELETE method above, only the _id, _rev and a deleted flag are preserved. If we deleted a document by adding “_deleted”:true then all the fields of the document are preserved. This is to allow, for example, to record the time we deleted a document, or the reason we deleted it.
7.6 COPY
Note that this is a non-standard extension to HTTP.
We can copy documents by sending an HTTP COPY request. This allows us to duplicate the contents (and attachments) of a document to a new document under a different document id without first retrieving it from CouchDB. Use the Destination header to specify the document that We want to copy to (the target document).
It is not possible to copy documents between databases and it is not (yet) possible to perform bulk copy operations.
COPY /somedatabase/some_doc HTTP/1.1 Destination: some_other_doc
If we want to overwrite an existing document, we need to specify the target document’s revision with a rev parameter in the Destination header:
COPY /somedatabase/some_doc HTTP/1.1 Destination: some_other_doc?rev=rev_id
The response in both cases includes the target document’s revision:
HTTP/1.1 201 Created
Server: CouchDB/0.9.0a730122-incubating (Erlang OTP/R12B)
Etag: "355068078"
Date: Mon, 05 Jan 2009 11:12:49 GMT
Content-Type: text/plain;charset=utf-8
Content-Length: 41
Cache-Control: must-revalidate
{"ok":true,"id":"some_other_doc","rev":"355068078"}7.7 All Documents
7.6.1 all_docs
To get a listing of all documents in a database, use the special _all_docs URI. This is a specialized View so the Querying Options of the HTTP_view_API apply here.
GET /somedatabase/_all_docs HTTP/1.0
This will return a listing of all documents and their revision IDs, ordered by DocID (case sensitive):
HTTP/1.1 200 OK
Date: Thu, 17 Aug 2006 05:39:28 +0000GMT
Content-Type: application/json
Connection: close
{
"total_rows": 3, "offset": 0, "rows": [
{"id": "doc1", "key": "doc1", "value": {"rev": "4324BB"}},
{"id": "doc2", "key": "doc2", "value": {"rev":"2441HF"}},
{"id": "doc3", "key": "doc3", "value": {"rev":"74EC24"}}
]
}Use the query argument descending=true to reverse the order of the output table:
Will return the same as before but in reverse order:
HTTP/1.1 200 OK
Date: Thu, 17 Aug 2006 05:39:28 +0000GMT
Content-Type: application/json
Connection: close
{
"total_rows": 3, "offset": 0, "rows": [
{"id": "doc3", "key": "doc3", "value": {"rev":"74EC24"}},
{"id": "doc2", "key": "doc2", "value": {"rev":"2441HF"}},
{"id": "doc1", "key": "doc1", "value": {"rev": "4324BB"}}
]
}
The query string parameters startkey, endkey and limit may also be used to limit the result set. For example:
GET /somedatabase/_all_docs?startkey="doc2"&limit=2 HTTP/1.0
Will return:
HTTP/1.1 200 OK
Date: Thu, 17 Aug 2006 05:39:28 +0000GMT
Content-Type: application/json
Connection: close
{
"total_rows": 3, "offset": 1, "rows": [
{"id": "doc2", "key": "doc2", "value": {"rev":"2441HF"}},
{"id": "doc3", "key": "doc3", "value": {"rev":"74EC24"}}
]
}
Use endkey if you are interested in a specific range of documents:
GET /somedatabase/_all_docs?startkey="doc2"&endkey="doc3" HTTP/1.0
This will get keys inbetween and including doc2 and doc3; e.g. doc2-b and doc234.
Both approaches can be combined with descending:
GET /somedatabase/_all_docs?startkey="doc2"&limit=2&descending=true HTTP/1.0
Will return:
HTTP/1.1 200 OK
Date: Thu, 17 Aug 2006 05:39:28 +0000GMT
Content-Type: application/json
Connection: close
{
"total_rows": 3, "offset": 1, "rows": [
{"id": "doc3", "key": "doc3", "value": {"rev":"74EC24"}},
{"id": "doc2", "key": "doc2", "value": {"rev":"2441HF"}}
]
}If we add include_docs=true to a request to _all_docs not only metadata but also the documents themselves are returned.
7.6.2 _changes
This allows us to see all the documents that were updated and deleted, in the order these actions are done:
GET /somedatabase/_changes HTTP/1.0
Will return something of the form:
HTTP/1.1 200 OK
Date: Fri, 8 May 2009 11:07:02 +0000GMT
Content-Type: application/json
Connection: close
{"results":[
{"seq":1,"id":"fresh","changes":[{"rev":"1-967a00dff5e02add41819138abb3284d"}]},
{"seq":3,"id":"updated","changes":[{"rev":"2-7051cbe5c8faecd085a3fa619e6e6337"}]},
{"seq":5,"id":"deleted","changes":[{"rev":"2-eec205a9d413992850a6e32678485900"}],"deleted":true}
],
"last_seq":5}All the view parameters work on _changes, such as startkey, include_docs etc. However, note that the startkey is exclusive when applied to this view. This allows for a usage pattern where the startkey is set to the sequence id of the last doc returned by the previous query. As the startkey is exclusive, the same document won’t be processed twice.
8. Replication
CouchDB replication is a mechanism to synchronize databases. Much like rsyncsynchronizes two directories locally or over a network, replication synchronizes two databases locally or remotely.
In a simple POST request, we tell CouchDB the source and the target of a replication and CouchDB will figure out which documents and new document revisions are on source that are not yet on target, and will proceed to move the missing documents and revisions over.
First, we will create a target database. Note that CouchDB would not automatically create a target database for us, and will return a replication failure if the target doesn’t exist:
curl -X PUT http://127.0.0.1:5984/shopcart-replica
Now we can use the database albums-replica as a replication target:
curl -vX POST http://127.0.0.1:5984/_replicate -d '{"source":"shopcart","target":"shopcart-replica"}' -H "Content-Type: application/json"