Rails is great for making traditional server-rendered web applications. It has support for cookies, sessions, and other browser-specific functionality right out of the box. It’s also great for building JSON APIs, but why include a whole bunch of functionality that we aren’t going to use if what we want is to simply build a JSON API?
That’s where using Rails in --api mode comes in handy. It gives us the power of Rails but with only the functionality that we’re actually going to need for our JSON API.
In this article, we’ll investigate how to take advantage of the rails-api gem, which, starting with Rails 5, now comes built in. We’ll look at how to generate different types of JSON responses using ActiveModel::Serializer and how to cache our JSON serialization. Lastly, we’ll look at how we can throttle requests to our API to avoid being taken down by abusive clients.
Using Rails in “API” mode
Before Rails 5, we could already use Rails in “API” mode, but we had to do so through a different gem, namely the rails-api gem. This past June, Santiago Pastorino opened up a pull-request (which has since been merged) requesting that rails-api be merged into core Rails. This change will be included when Rails 5 launches.
Using Rails 5 Right Now
It is possible to use Rails 5 right now, although you might want to proceed with caution since it isn’t exactly ready for prime time. Here are the steps to take to use Rails 5 in API mode today:
- Ensure you have Ruby 2.2 or higher.
- Install Rails from master branch:
git clone git@github.com:rails/rails.git - Now it’s time to generate a new Rails API application. We do that by passing the
--apidirective to therails newcommand.
Because we are using Rails 5 before it’s officially ready, we’re going to need to run this command from within the directory we just cloned Rails into. We’ll also pass the --edge directive:
bundle exec railties/exe/rails new <parent-folder-path>/api_app_name --api --edge
Because we’re installing Rails in edge mode, it will install a few gems into the Gemfile that we don’t actually need. These are sprockets-rails, sprockets, and sass-rails. Leave them for now because --edge Rails seems to need them.
Once Rails 5 officially launches, we’ll simply need to run the rails new --api command, and it won’t come with these “view” related gems.
What makes API mode different?
For the most part, what the API mode does is remove functionality that you don’t actually need when building an API. This includes things like sessions, cookies, assets, and really anything related to making Rails work with a browser. It will also change the generators so that it won’t generate views, helpers, and assets when generating a new resource.
Specifically, when running rake middleware on both an –api app and a normal app, the normal app includes the following middleware that the API doesn’t:
use #<ActiveSupport::Cache::Strategy::LocalCache::Middleware:0x007fa7511b02b0> use Rack::MethodOverride use WebConsole::Middleware use ActionDispatch::Cookies use ActionDispatch::Session::CookieStore use ActionDispatch::Flash
The difference can also be seen when you compare the ApplicationController on a web app versus an API app. The web version extends from ActionController::Base, whereas the API version extends from ActionController::API, which includes a much smaller subset of functionality.
The web ApplicationController:
class ApplicationController < ActionController::Base # Prevent CSRF attacks by raising an exception. # For APIs, you may want to use :null_session instead. protect_from_forgery with: :exception end
The API ApplicationController:
class ApplicationController < ActionController::API end
Let’s generate some scaffolding for a RentalUnit model with the following command:
bin/rails g scaffold rental_unit address rooms:integer bathrooms:integer price_cents:integer
If we look at the folders and files that got created, we’ll notice that it hasn’t included any of the normal view files that get created when you generate scaffolding in a normal Rails app.
invoke active_record create db/migrate/20150906194623_create_rental_units.rb create app/models/rental_unit.rb invoke test_unit create test/models/rental_unit_test.rb create test/fixtures/rental_units.yml invoke resource_route route resources :rental_units create app/serializers/rental_unit_serializer.rb invoke scaffold_controller create app/controllers/rental_units_controller.rb invoke test_unit create test/controllers/rental_units_controller_test.rb
Responding with JSON
It’s possible that you want to respond with XML, but it’s a fairly safe assumption that you’re going to be responding with JSON. This is where Rails API shines. Before we get to how to respond easily with JSON, let’s talk about which format our JSON should be in.
JSON formats
Should we include a root node when responding with multiple objects? What about with single objects? Where do we put meta information, and how do we embed nested or related data?
There are a ton of other questions like these that you can ask (and argue about) when trying to decide how the JSON should look but, luckily, there are standards you can follow. json:api, popularized by the Ember (and Rails) community, seems to be winning the battle right now and can serve as an anti-bikeshedding tool.
The JSON serializer we’ll be using in these examples allows us to easily respond in this format.
Serializing our JSON responses
ActiveModel::Serializer is included by default in your Gemfile when you create an application using the --api directive.
ActiveModel::Serializer allows you to define which attributes and relationships you would like to include in your JSON response. It also acts as a presenter where you can define custom methods to display extra information or override how it’s displayed in your JSON.
The data we’re working with for this article has two models: a RentalUnit and a User, where the RentalUnit belongs to a User, and the User has many Rental Units.
In our RentalUnit serializer, we define which attributes to include in the response. Attributes can be anything that the RentalUnit object responds to. price and price_per_room aren’t real attributes but are methods that we’ve defined in the model. Here we can also say that we want to include the User data along with the RentalUnit by using the belongs_to method, much like in Active Record.
class RentalUnitSerializer < ActiveModel::Serializer attributes :id, :address, :rooms, :bathrooms, :price, :price_per_room belongs_to :user end
In our User serializer, we’ll actually override how the name field is displayed in the JSON response. For the sake of privacy, we don’t want to include the full name and are only going to include the first initial followed by their last name. This simple example will fail for Prince, Madonna, and other single-name celebrities, but it’ll do for now. We have access to the object which is whatever object you are currently serializing.
class UserSerializer < ActiveModel::Serializer
attributes :id, :name, :email
def name
names = object.name.split(" ")
"#{names[0].first}. #{names[1][1]}"
end
endIf we make a request to /rental_units/1, we’ll get a JSON response like this:
{"id":1,"address":"460 Jane St.","rooms":2,"bathrooms":2,"price":900.0,"price_per_room":450.0,"user":{"id":1,"name":"A. Serna","email":"email1@sample.com"}}You’ll notice that by default it isn’t in the json:api format. To change it to this format, we simply have to declare an initializer to tell ActiveModel::Serializer how to serialize the JSON data.
# config/initializers/active_model_serializer.rb ActiveModel::Serializer.config.adapter = ActiveModel::Serializer::Adapter::JsonApi
If we refresh the page (you may have to restart your Rails server after making this change), you’ll see that the data is now in the json:api format.
{"data":{"id":"1","type":"rental_units","attributes":{"address":"460 Jane St.","rooms":2,"bathrooms":2,"price":900.0,"price_per_room":450.0},"relationships":{"user":{"data":{"type":"users","id":"1"}}}}}Caching
Caching is important when dealing with APIs, especially if your API is read-heavy, the data doesn’t change very often, or the responses are slow to generate.
If the accuracy of your data doesn’t need to be perfect — meaning you can afford to serve data that’s a few seconds out of date (or when your data doesn’t change much after its creation) — one of the best ways to speed up your site is to avoid a request hitting your Rails application at all. Using something like Varnish Cache, a reverse proxy server can serve cached versions of your content based on different TTLs. The fastest work is the work that doesn’t need to be done.
With ActiveModel::Serializer (AMS), you get full-object caching and fragment caching. These types of caching will not save you time making SQL queries but will save you time if serializing your objects is a time-consuming process. Things that can make it time consuming include objects that have a ton of fields to serialize or if certain fields are costly to generate. Hitting the database is still required because normally cache expiration is done based on the database ID of the object as well as its updated_at field. This can of course be overridden, but I’ve found that it is generally the best approach.
Implementing caching
To use caching with AMS, you’ll first need to decide what cache store your Rails application will use. Popular choices are Memcached or Redis. For this example, we’ll be using Memcached.
The first step is to set which cache store we’ll be using. Next, we’ll turn on caching in the development environment so that we can see its results. This is done in the config/environments/development.rb file. Be careful where you put it because in development mode, Rails includes code in this file to disable caching. We’re going to override this so that we can test it out locally. Alternatively, you could launch your site locally in production mode.
# config/environments/development.rb config.cache_store = :mem_cache_store, "localhost" config.action_controller.perform_caching = true
You’ll also need to include the dalli gem to your Gemfile which is used to talk to Memcached.
gem 'dalli', '~> 2.7.4'
The last step is to tell our serializer what to cache. To our rental_unit_serializer.rb file, we’ll add the following line:
class RentalUnitSerializer < ActiveModel::Serializer cache key: 'rental_unit' attributes :id, :address, :rooms, :bathrooms, :price, :price_per_room belongs_to :user end
This will end up caching the entire serialization of the object. For fragment caching, you can pass the options only or except to have more fine-grained control over what is cached and what isn’t.
By making these changes, we’ve changed our response time from 30ms to 50ms… wait, what? Yes, you heard me right. By adding cache, responses in my application have actually slowed down.
Caching quagmires
I’ll be honest that this wasn’t the result I was expecting. The whole reason you add cache to your application is to speed up response time, not slow it down. So I did two things: I reached out to one of the core contributors (and the person who worked on caching) of AMS and asked what his opinion was, and I also broke out some flame graphs to see what was happening inside of my application.
Because the application I am testing with isn’t exactly “real-world” (there are only about six fields that I am serializing), it seems faster to actually just regenerate the JSON rather than to go and fetch the cached version of the response.
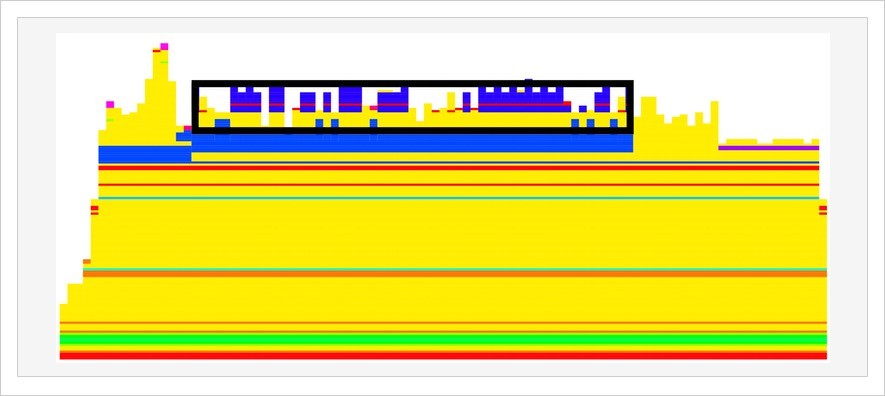
By looking at the flame graph with caching turned on, I could tell that 48 percent of the time was spent in the cache_check method or farther down in the stack trace. This seems to account for the slowdown from 30ms to 50ms.
active_model_serializers-258f116c3cf5/lib/active_model/serializer/adapter.rb:110:in `cache_check' (48 samples - 48.00%)
Here’s an image of the flamegraph, which was produced by using rack mini profiler gem with the flamegraph gem. I’ve highlighted in black the portion that’s dealing with the cache.
Support for Russian Doll caching
At the moment Russian Doll caching isn’t supported with AMS. There is good news, though! João Moura wrote about the current state and future of AMS and mentioned that Russian Doll caching is planned. He’s hopeful that it will be ready before Rails 5 is released.
Another option if you would like to use Russian Doll caching now is to forgo using AMS and use Jbuilder to generate your JSON responses. Jbuilder supports Russian Doll caching, although if you want to also respond using the json:api format, you’ll have to craft the correctly formatted response yourself.
Rate Limiting / Throttling
One important thing to think about when you have an API is to be able to limit the amount of requests that can be made. This is important either to be able to stop abuse or perhaps based on the amount of access that your users have paid for (free users get fewer requests per hour than paid users).
Middleware to the rescue
To help us with rate limiting, we’ll turn to Rack middleware. Middleware is essentially how Rails (and other web frameworks) hook into Rack. The request flows through a stack of middleware objects calling call on each one, passing the request along, allowing each middleware to either modify it and call the next middleware in the stack, or to halt the request by returning a response.
The middleware we will be using will be slotted into the middleware stack before we get to the main Rails middleware. It will allow us to look at the request, determine if we will allow it to continue to our API and be processed normally, or if we want to deny the request because the user has reached their allowed limit.
Rack::Attack
Rack::Attack is a gem released by Kickstarter to help throttle website (or API) usage. It is middleware that allows us to:
- whitelist: Allowing it to process normally if certain conditions are true
- blacklist: Sending a denied message instantly for certain requests
- throttle: Checking if the user is within their allowed usage
- track: Tracking this request to be able to log certain information about our requests
Usage
Rack::Attack is installed with just a few steps. The first step is to add it to your Gemfile:
# Gemfile gem 'rack-attack'
Once you’ve got it in your Gemfile, you’ll want to insert it into your middleware stack. This is done in the config/application.rb file.
# config/application.rb config.middleware.use Rack::Attack
Rack::Attack by default is configured to use the Rails.cache, but we can override that if we want by setting the Rack::Attack.cache.store value in our Rack::Attack class.
# initializers/rack_attack.rb class Rack::Attack Rack::Attack.cache.store = ActiveSupport::Cache::MemoryStore.new end
Deciding what to throttle on
There are many things we can throttle on. We can throttle by IP address, by API key, control it per path or action, etc. All of these things are done within the throttle call that goes inside of our initializer.
Here’s a simple setup which will allow an IP address to make 10 requests every 10 seconds.
throttle('req/ip', limit: 10, period: 10) do |req|
req.ip
endOnce the user reaches the limit, we’re going to want to respond to them that they will need to retry once their threshold period starts over again. By default, it will respond with text/html, but since we’re building a JSON API, we can override that to respond with a custom message and the correct mime type.
The message conforms to the Rack standard of a callable object (in this case a lambda) which returns an array with three values: HTTP response code, a hash of HTTP headers, and an array of strings which is the body of the response.
self.throttled_response = ->(env) {
retry_after = (env['rack.attack.match_data'] || {})[:period]
[
429,
{'Content-Type' => 'application/json', 'Retry-After' => retry_after.to_s},
[{error: "Throttle limit reached. Retry later."}.to_json]
]
}We are also able to whitelist certain requests. Maybe everyone no matter what can access a certain path, or requests made from a special internal IP address are always allowed through.
whitelist('allow-localhost') do |req|
'127.0.0.1' == req.ip || '::1' == req.ip
endIf we take a look at the finished Rack::Attack code, it looks like this:
class Rack::Attack
Rack::Attack.cache.store = ActiveSupport::Cache::MemoryStore.new
whitelist('allow-localhost') do |req|
'127.0.0.1' == req.ip || '::1' == req.ip
end
throttle('req/ip', limit: 10, period: 10) do |req|
req.ip
end
self.throttled_response = ->(env) {
retry_after = (env['rack.attack.match_data'] || {})[:period]
[
429,
{'Content-Type' => 'application/json', 'Retry-After' => retry_after.to_s},
[{error: "Throttle limit reached. Retry later."}.to_json]
]
}
endTracking API access with Rack::Attack
There are a couple ways we can track our API access using Rack::Attack. When Rack::Attack either throttles or tracks requests to the API, it will instrument a notification using the ActiveSupport::Notifications interface.
We can then set up subscribers to those events and choose how we want to handle them. In this case, we want to just log using Rails.logger when someone triggers a throttled access attempt. This way we can use something like Splunk to query against our Rails logs.
I’ve chosen to create an initializer file where I can put the notification subscriptions. Here I can subscribe to the rack.atack notifications and check what type of match was triggered. In this case, I’m looked for throttled events. I also have access to the request object, allowing me to pull out the user’s IP address.
# initializers/notifications.rb
ActiveSupport::Notifications.subscribe("rack.attack") do |name, start, finish, request_id, req|
if req.env['rack.attack.match_type'] == :throttle
Rails.logger.info "Throttled IP: #{req.ip}"
end
endSummary
In this article, we took a look at how we can take advantage of the ability to create an API-specific Rails app which will be available to us starting in Rails 5. You can still use Rails as an API now, but you will have to include a separate rails-api gem. You also won’t be able to create it with the rails new --api command.
We also looked at how we can respond using the json:api format using ActiveModel::Serializer. Then we looked at how we can cache our JSON serialization in AMS and how to throttle abusive clients from overloading our API (and ruining performance for the rest of our users).
Bottom line: Rails API gives us the full power of Rails without the bloat of unnecessary functionality.
| Reference: | Building a JSON API with Rails 5 from our WCG partner Florian Motlik at the Codeship Blog blog. |
