Docker Service Discovery On Microsoft Azure – Docker Java App Load Balanced By Nginx Or Apache HTTP, Mongo Replica Set And Hazelcast Cluster
This project covers three service discovery use cases in Docker application deployments — including Nginx & Apache HTTP Server load balancing, Mongo Replica Set and Hazelcast Cluster. The service discovery framework in DCHQ provides event-driven life-cycle stages that executes custom scripts to re-configure application components. This is critical when scaling out clusters for which a load balancer may need to be re-configured or a replica set may need to be re-balanced.
The service discovery framework in DCHQ is by no means a replacement to the tools that are dedicated to service discovery. These include: Consul, etcd, and ZooKeeper to name a few. In fact, this article includes an example of deploying a multi-tier Java application with Consul & Registrator using DCHQ.
https://www.youtube.com/watch?v=_d39kUBMNj0
This article explores why service discovery is needed in Docker application deployments and the common ways to address the challenges with service discovery.
To run & manage the 5 application templates in this project on 15+ different clouds and virtualization platforms (including vSphere, OpenStack, AWS, Rackspace, Microsoft Azure, Google Compute Engine, DigitalOcean, IBM SoftLayer, etc.), make sure that you either:
- Sign Up for FREE on DCHQ.io — http://dchq.io (no credit card required), or
- Download DCHQ On-Premise Standard Edition for FREE — http://dchq.co/dchq-on-premise-download.html
![]()
Background
To unleash the power of Docker containers for distributed application deployments across multiple servers (or even regions), one must not be restricted to defining in advance which service goes to which server. The dynamic scalability (or auto scaling) requirements in critical environments (like production) do not just apply to the new microservices architectures — but they also apply to the typical monolithic application deployments. The automatic scaling of services would be difficult at best if these services were bound to specific servers that may be at risk of becoming resource constrained or completely unavailable.
In order to be able to “discover” our services, we need the following.
- Service registration to store the host and the port the service is running on.
- Service discovery to be able to “discover” the information we stored during the registration process.
These high-level requirements are needed to address the actual use cases for service discovery. These include the following:
- How do we unregister a service if it stops working?
- How do we balance the load among the “discovered” services?
- What happens if a service is added or removed during a typical scale out or scale in?
Most of the typical service discovery tools feature some kind of highly available distributed key/value storage. You can check out this blog for a detailed comparison of the different tools available.
The main downsides of these tools is their reliance on 3rd party tools and the fact that they themselves run on containers. In order to use Consul, for example, a user needs to run both Consul and Registrator containers in the application — which will ultimately increase the number of containers that users have to manage in general.
DCHQ, on the other hand, uses the agent to orchestrate both the registration and the service discovery — where the information is stored in the underlying DCHQ database. This means that no additional containers are needed. Moreover, the service discovery framework provides more flexibility by allowing users to customize the scripts that need to be executed at certain events while leveraging not just the IP & hostname information of other containers in the application, but also the environment variable values used at deployment time.
This does not mean that the usage of DCHQ’s service discovery framework should replace other tools used. The best results are obtained when you use right tools for the job.
In this blog, we will cover three service discovery use cases in Docker application deployments — including Nginx & Apache HTTP Server load balancing, Mongo Replica Set and Hazelcast Cluster.
We will cover:
- Building the YAML-based application templates that can re-used on any Linux host running anywhere
- Provisioning & auto-scaling the underlying infrastructure on any cloud (with Microsoft Azure being the example in this blog)
- Deploying the Distributed, Highly Available Applications on the Microsoft Azure Cluster
- Monitoring the CPU, Memory & I/O of the Running Containers
- Scaling out the Tomcat Application Server Cluster
- Scaling out the Mongo Replica Set Cluster
- Scaling out the Hazelcast Cluster
Building the YAML-based application templates that can re-used on any Linux host running anywhere
Once logged in to DCHQ (either the hosted DCHQ.io or on-premise version), a user can navigate to Manage > App/Machine and then click on the + button to create a new Docker Compose template.
We have created 5 application templates using the official images from Docker Hub.
The templates include examples of the following application stacks:
- Multi-Tier Java Application with Nginx, Tomcat, Solr and Mongo — using Consul and Registrator for service discovery
- Multi-Tier Java Application with Nginx, Tomcat, Solr and Mongo — using DCHQ’s service discovery framework
- Multi-Tier Java Application with Apache HTTP Server, Tomcat, Solr, and Cassandra) — using DCHQ’s service discovery framework
- Mongo Replica Set — using DCHQ’s service discovery framework
- Hazelcast Cluster — using DCHQ’s service discovery framework
For more information about Docker application modeling in DCHQ, check out DCHQ’s detailed documentation on Docker Compose templates: http://dchq.co/docker-compose.html
Plug-ins to Configure Web Servers and Application Servers at Request Time & Post-Provision
Across all these application templates, you will notice that some of the containers are invoking BASH script plug-ins at request time in order to configure the container. These plug-ins can be executed post-provision as well.
These plug-ins can be created by navigating to Manage > Plug-ins. Once the BASH script is provided, the DCHQ agent will execute this script inside the container. A user can specify arguments that can be overridden at request time and post-provision. Anything preceded by the $ sign is considered an argument — for example, $file_url can be an argument that allows developers to specify the download URL for a WAR file. This can be overridden at request time and post-provision when a user wants to refresh the Java WAR file on a running container for example.
The plug-in ID needs to be provided when defining the YAML-based application template. For example, to invoke a BASH script plug-in for Nginx, we would reference the plug-in ID as follows:
Nginx:
image: nginx:latest
publish_all: true
mem_min: 50m
host: host1
plugins:
- !plugin
id: 0H1Nk
restart: true
lifecycle: on_create, post_scale_out:AppServer, post_scale_in:AppServer, post_stop:AppServer, post_start:AppServer
arguments:
# Use container_private_ip if you're using Docker networking
- servers=server {{AppServer | container_private_ip}}:8080;
# Use container_hostname if you're using Weave networking
#- servers=server {{AppServer | container_hostname}}:8080;You will notice that the same Nginx plug-in is getting executed during these different stages or events:
- When the Nginx container is created — in this case, the container IP’s of the application servers are injected into the default configuration file to facilitate the load balancing to the right services
- When the application server cluster is scaled in or scale out — in this case, the updated container IP’s of the application servers are injected into the default configuration file to facilitate the load balancing to the right services
- When the application servers are stopped or started — in this case, the updated container IP’s of the application servers are injected into the default configuration file to facilitate the load balancing to the right services
So the service discovery framework here is doing both service registration (by keeping track of the container IP’s and environment variable values) and service discovery (by executing the right scripts during certain events or stages).
Service Discovery with plug-in life-cycle stages
The lifecycle parameter in plug-ins allows you to specify the exact stage or event to execute the plug-in. If no lifecycle is specified, then by default, the plug-in will be execute on_create. Here are the supported lifecycle stages:
- on_create — executes the plug-in when creating the container
- on_start — executes the plug-in after a container starts
- on_stop — executes the plug-in before a container stops
- on_destroy — executes the plug-in before destroying a container
- post_create — executes the plug-in after the container is created and running
- post_start[:Node] — executes the plug-in after another container starts
- post_stop[:Node] — executes the plug-in after another container stops
- post_destroy[:Node] — executes the plug-in after another container is destroyed
- post_scale_out[:Node] — executes the plug-in after another cluster of containers is scaled out
- post_scale_in[:Node] — executes the plug-in after another cluster of containers is scaled in
To get access to the Nginx, Apache HTTP Server (httpd), Mongo Replica Set, and Hazelcast Cluster plug-ins under the EULA license, make sure you either:
- Sign Up for FREE on DCHQ.io — http://dchq.io (no credit card required)
- Download DCHQ On-Premise Standard Edition for FREE — http://dchq.co/dchq-on-premise-download.html
cluster_size and host parameters for HA deployment across multiple hosts
You will notice that the cluster_size parameter allows you to specify the number of containers to launch (with the same application dependencies).
The host parameter allows you to specify the host you would like to use for container deployments. This is possible if you have selected Weave as the networking layer when creating your clusters. That way you can ensure high-availability for your application server clusters across different hosts (or regions) and you can comply with affinity rules to ensure that the database runs on a separate host for example. Here are the values supported for the host parameter:
- host1, host2, host3, etc. – selects a host randomly within a data-center (or cluster) for container deployments
- IP Address 1, IP Address 2, etc. — allows a user to specify the actual IP addresses to use for container deployments
- Hostname 1, Hostname 2, etc. — allows a user to specify the actual hostnames to use for container deployments
- Wildcards (e.g. “db-”, or “app-srv-”) – to specify the wildcards to use within a hostname
Environment Variable Bindings Across Images
Additionally, a user can create cross-image environment variable bindings by making a reference to another image’s environment variable. In this case, we have made several bindings – including mongo_url={{Mongo|container_private_ip}}:27017/dchq – in which the database container name is resolved dynamically at request time and is used to ensure that the application servers can establish a connection with the database.
Here is a list of supported environment variable values:
- {{alphanumeric | 8}} – creates a random 8-character alphanumeric string. This is most useful for creating random passwords.
- {{Image Name | ip}} – allows you to enter the host IP address of a container as a value for an environment variable. This is most useful for allowing the middleware tier to establish a connection with the database.
- {{Image Name | container_ip}} – allows you to enter the name of a container as a value for an environment variable. This is most useful for allowing the middleware tier to establish a secure connection with the database (without exposing the database port).
- {{Image Name | container_private_ip}} – allows you to enter the internal IP of a container as a value for an environment variable. This is most useful for allowing the middleware tier to establish a secure connection with the database (without exposing the database port).
- {{Image Name | port_Port Number}} – allows you to enter the Port number of a container as a value for an environment variable. This is most useful for allowing the middleware tier to establish a connection with the database. In this case, the port number specified needs to be the internal port number – i.e. not the external port that is allocated to the container. For example, {{PostgreSQL | port_5432}} will be translated to the actual external port that will allow the middleware tier to establish a connection with the database.
- {{Image Name | Environment Variable Name}} – allows you to enter the value an image’s environment variable into another image’s environment variable. The use cases here are endless – as most multi-tier applications will have cross-image dependencies.
Building the Nginx Docker Image for Consul
The Dockerfile and configuration files for building the Nginx Docker Image for Consul can be found here: https://github.com/dchqinc/nginx-consul
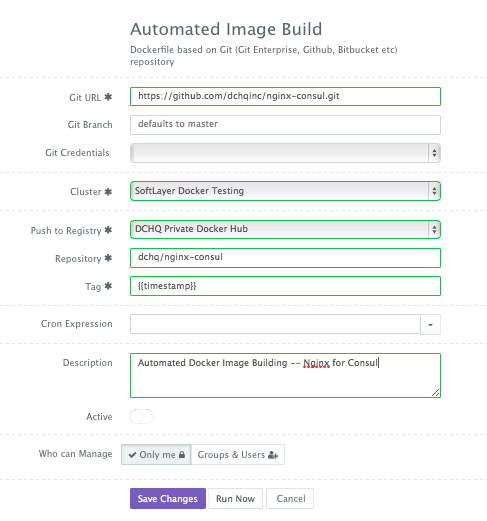
Once logged in to DCHQ (either the hosted DCHQ.io or on-premise version), a user can navigate to Manage > Image Build and then click on the + button to create a new Dockerfile (Git/GitHub/BitBucket) image build.
Provide the required values as follows:
- Git URL – https://github.com/dchqinc/nginx-consul.git
- Git Branch – this field is optional — but a user can specify a branch from a GitHub project. The default branch is master.
- Git Credentials – a user can store the credentials to a private GitHub repository securely in DCHQ. This can be done by navigating to Manage > Cloud Providers and Repos and clicking on the + to select Credentials
- Cluster – the building of Docker images is orchestrated through the DCHQ agent. As a result, a user needs to select a cluster on which an agent will be used to execute the building of Docker images. If a cluster has not been created yet, please refer to this section to either register already running hosts or automate the provisioning of new virtual infrastructure.
- Push to Registry – a user can push the newly created image on either a public or private repository on Docker Hub or Quay. To register a Docker Hub or Quay account, a user should navigate to Manage > Cloud Providers and clicking on the + to select Docker Registries
- Repository – this is the name of the repository on which the image will be pushed. For example, our image was pushed to dchq/nginx-consul:latest
- Tag – this is the tag name that you would like to give for the new image. The supported tag names in DCHQ include:
- {{date}} — formatted date
- {{timestamp}} — the full time-stamp
- Cron Expression – a user can schedule the building of Docker images using out-of-box cron expressions. This facilitates daily and nightly builds for users.
Once the required fields are completed, a user can click Save. A user can then click on the Play Button to build the Docker image on-demand.
Multi-Tier Java (Consul-Nginx-Tomcat-Solr-Mongo)
![]()
Nginx:
image: dchq/nginx-consul:latest
publish_all: true
mem_min: 50m
host: host1
plugins:
- !plugin
id: GINmu
restart: true
lifecycle: on_create
arguments:
- APPSERVER_IP={{AppServer | container_private_ip}}
- SERVICE_NAME={{AppServer | SERVICE_NAME}}
- SERVICE_TAGS={{AppServer | SERVICE_TAGS}}
- CONSUL_IP={{Consul | container_private_ip}}
AppServer:
image: tomcat:8.0.21-jre8
mem_min: 600m
host: host1
cluster_size: 1
environment:
- mongo_url={{Mongo|container_private_ip}}:27017/dchq
- solr_host={{Solr|container_private_ip}}
- solr_port=8983
- SERVICE_NAME=app
- SERVICE_TAGS=production
plugins:
- !plugin
id: oncXN
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-solr-mongo-cassandra-example/raw/master/dbconnect.war
- dir=/usr/local/tomcat/webapps/ROOT.war
- delete_dir=/usr/local/tomcat/webapps/ROOT
Consul:
image: progrium/consul:latest
host: host1
ports:
- "8300:8300"
- "8400:8400"
- "8500:8500"
- "8600:53/udp"
command: -server -bootstrap -advertise 10.0.2.15
Registrator:
image: gliderlabs/registrator:latest
host: host1
command: consul://<HOST_IP>:8500
volumes:
- "/var/run/docker.sock:/tmp/docker.sock"
Solr:
image: solr:latest
mem_min: 300m
host: host1
publish_all: false
plugins:
- !plugin
id: doX8s
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-solr-mongo-cassandra-example/raw/master/names.zip
Mongo:
image: mongo:latest
host: host1
mem_min: 400mMulti-Tier Java (ApacheLB-Tomcat-Solr-Mongo)
![]()
HTTP-LB:
image: httpd:latest
publish_all: true
mem_min: 50m
host: host1
plugins:
- !plugin
id: uazUi
restart: true
lifecycle: on_create, post_scale_out:AppServer, post_scale_in:AppServer
arguments:
# Use container_private_ip if you're using Docker networking
- BalancerMembers=BalancerMember http://{{AppServer | container_private_ip}}:8080
# Use container_hostname if you're using Weave networking
#- BalancerMembers=BalancerMember http://{{AppServer | container_hostname}}:8080
AppServer:
image: tomcat:8.0.21-jre8
mem_min: 600m
host: host1
cluster_size: 1
environment:
- mongo_url={{Mongo|container_private_ip}}:27017/dchq
- solr_host={{Solr|container_private_ip}}
- solr_port=8983
plugins:
- !plugin
id: oncXN
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-solr-mongo-cassandra-example/raw/master/dbconnect.war
- dir=/usr/local/tomcat/webapps/ROOT.war
- delete_dir=/usr/local/tomcat/webapps/ROOT
Solr:
image: solr:latest
mem_min: 300m
host: host1
publish_all: false
plugins:
- !plugin
id: doX8s
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-solr-mongo-cassandra-example/raw/master/names.zip
Mongo:
image: mongo:latest
host: host1
mem_min: 400mMulti-Tier Java (Nginx-Tomcat-Solr-MySQL)
![]()
Nginx:
image: nginx:latest
publish_all: true
mem_min: 50m
host: host1
plugins:
- !plugin
id: 0H1Nk
restart: true
lifecycle: on_create, post_scale_out:AppServer, post_scale_in:AppServer
arguments:
# Use container_private_ip if you're using Docker networking
- servers=server {{AppServer | container_private_ip}}:8080;
# Use container_hostname if you're using Weave networking
#- servers=server {{AppServer | container_hostname}}:8080;
AppServer:
image: tomcat:8.0.21-jre8
mem_min: 600m
host: host1
cluster_size: 1
environment:
- database_driverClassName=com.mysql.jdbc.Driver
- database_url=jdbc:mysql://{{MySQL|container_hostname}}:3306/{{MySQL|MYSQL_DATABASE}}
- database_username={{MySQL|MYSQL_USER}}
- database_password={{MySQL|MYSQL_ROOT_PASSWORD}}
- solr_host={{Solr|container_private_ip}}
- solr_port=8983
plugins:
- !plugin
id: oncXN
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-solr-mongo-cassandra-example/raw/master/dbconnect.war
- dir=/usr/local/tomcat/webapps/ROOT.war
- delete_dir=/usr/local/tomcat/webapps/ROOT
Solr:
image: solr:latest
mem_min: 300m
host: host1
publish_all: false
plugins:
- !plugin
id: doX8s
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-solr-mongo-cassandra-example/raw/master/names.zip
MySQL:
image: mysql:latest
host: host1
mem_min: 400m
environment:
- MYSQL_USER=root
- MYSQL_DATABASE=names
- MYSQL_ROOT_PASSWORD={{alphanumeric|8}}Mongo Replica Set Cluster
![]()
mongo_rs1_srv1:
image: mongo:latest
mem_min: 400m
publish_all: true
command: --replSet rs1
environment:
# inject clustered node ips
- MONGO_RS1_SRV2_IP={{mongo_rs1_srv2|container_private_ip}}
# The above mapping will insert comma separated ip list e.g. 10.1.1.1,10.1.12
plugins:
- !plugin
# This plugin initializes the Replica Set
lifecycle: on_create
id: QX25F
- !plugin
# This plug-in re-balances the Replica Set post scale out
lifecycle: post_scale_out:mongo_rs1_srv2
id: sxKM9
- !plugin
# This plug-in re-balances the Replica Set post scale in
lifecycle: post_scale_in:mongo_rs1_srv2
id: YIALH
# Define this node as clustered
mongo_rs1_srv2:
image: mongo:latest
mem_min: 400m
cpu_shares: 1
cluster_size: 2
command: --replSet rs1Hazelcast Cluster
![]()
Hazelcast-Management-Center:
image: hazelcast/management-center:latest
# Use this configuration if deploying to a shared VM
publish_all: true
# (Recommended) Use this configuration if deploying to a dedicated VM
#ports:
# - 8080:8080
host: host1
environment:
- HAZELCAST_IP={{Hazelcast | container_private_ip}}
Hazelcast:
image: hazelcast/hazelcast:latest
# Use this configuration if deploying to a shared VM
publish_all: true
# (Recommended) Use this configuration if deploying to a dedicated VM
#ports:
# - 5701:5701
cluster_size: 1
host: host1
plugins:
- !plugin
id: Qgp4H
lifecycle: post_create, post_scale_out:Hazelcast, post_scale_in:Hazelcast
restart: true
arguments:
# Use this configuration if deploying to a shared VM
- Hazelcast_IP=<member>{{Hazelcast | container_private_ip}}</member>
# (Recommended) Use this configuration if deplying to a dedicated VM
#- Hazelcast_IP=<member>{{Hazelcast | ip}}</member>
- Management_Center_URL=http://{{Hazelcast-Management-Center | ip}}:{{Hazelcast-Management-Center | port_8080}}/mancenter
environment:
# Uncomment the line below to specify the heap size
#- MIN_HEAP_SIZE="1g"
# Uncomment the line below to provide your own hazelcast.xml file
- JAVA_OPTS=-Dhazelcast.config=/opt/hazelcast/hazelcast.xml
volumes:
# Uncomment the line below if you plan to use your own hazelcast.xml file
#- ./configFolder:./configFolderProvisioning & Auto-Scaling the Docker-enabled Infrastructure on Microsoft Azure
Once an application is saved, a user can register a Cloud Provider to automate the provisioning and auto-scaling of Docker-enabled clusters on 18 different cloud end-points including VMware vSphere, OpenStack, CloudStack, Amazon Web Services, Rackspace, Microsoft Azure, DigitalOcean, IBM SoftLayer, Google Compute Engine, and many others.
This example focuses on Microsoft Azure, but here’s a list of examples for some popular clouds & virtaulization platforms.
- DigitalOcean: http://dchq.co/docker-digitalocean.html
- Amazon Elastic Cloud Computing (EC2): http://dchq.co/docker-aws.html
- Microsoft Azure: http://dchq.co/docker-azure.html
- Rackspace: http://dchq.co/docker-rackspace.html
- IBM SoftLayer: http://dchq.co/docker-softlayer.html
- VMware vSphere: http://dchq.co/docker-vsphere.html
Before creating a Cloud Provider, you will need to create a private key and then generate a certificate that needs to be uploaded in the Microsoft Azure Console under Settings > Management Certificates.
To create a private key, you can use this command:
openssl req -x509 -nodes -days 365 -newkey rsa:1024 -keyout <key-name>.pem -out <key-name>.pem
Then generate a certificate using this private key:
openssl x509 -inform pem -in <key-name>.pem -outform der -out <cer-name>.cer
Upload the certificate in the Microsoft Azure Console under Settings > Management Certificates.
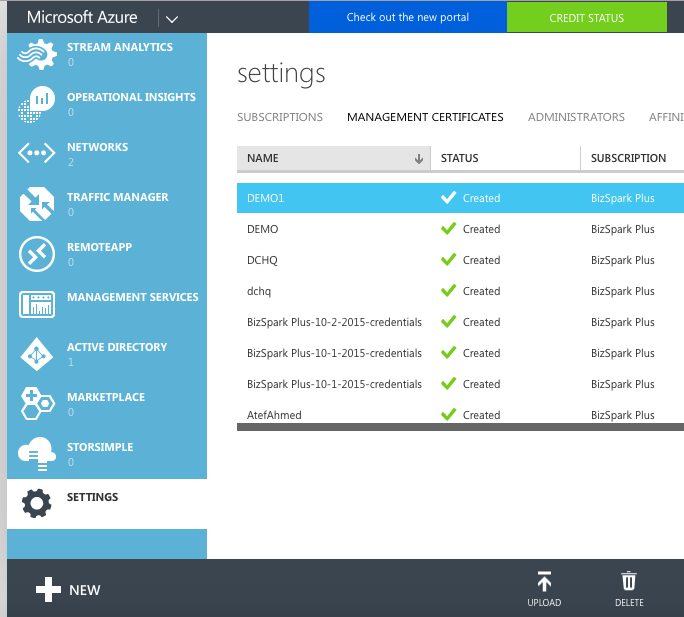
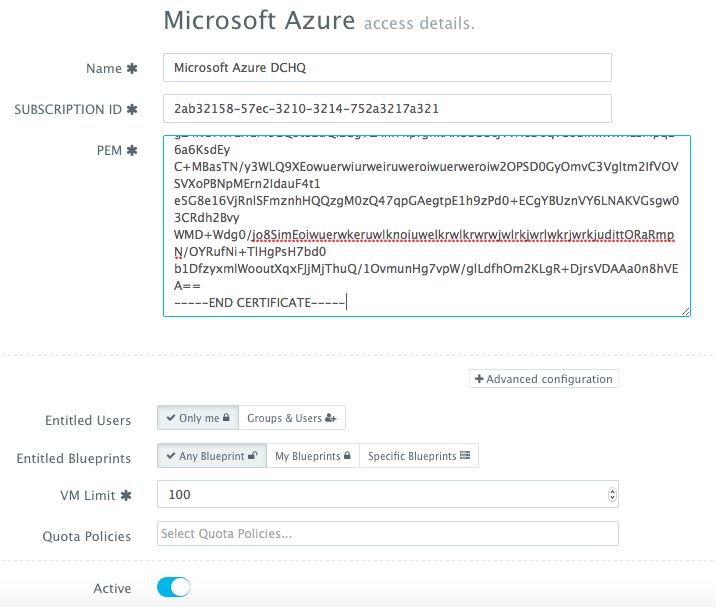
You can then register a Cloud Provider for Microsoft Azure by navigating to Manage > Cloud Providers and then clicking on the + button to select Microsoft Azure. The only required fields are: Subscription ID Private Key — this the key that you would have created in the previous step
The optional fields allow you to enforce granular access controls and associate this provider with a quota policy.
- Entitled Users — these are the users who are allowed to use this Cloud Provider for infrastructure provisioning. The entitled users do not have permission to manage or delete this cloud provider and will not be able to view any of the credentials.
- Entitled Blueprints — these are the Machine Compose templates that can be used with this cloud provider. For example, if a Tenant Admin wishes to restrict users to provisioning 4GB machines on certified operating systems, then users will not be able to use this cloud provider to provision any other machine.
- VM Limit — this is the maximum number of virtual machines that can be used with this cloud provider Quota Policies — these are pre-defined policies for setting quotas on the number of VM’s or the cost of VM’s. Multiple quota policies can be selected to customize controls per user or per group of users.
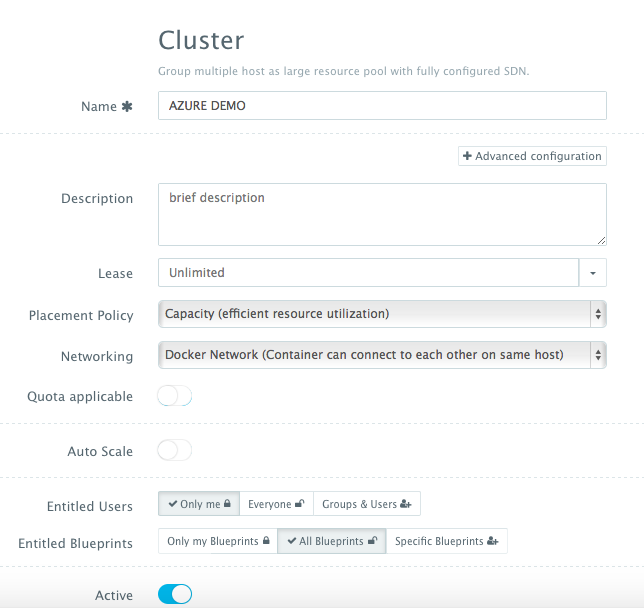
Servers across hybrid clouds or local development machines can be associated with a cluster, which is a logical mapping of infrastructure. A user can create a cluster by navigating to Manage > Clusters page and then clicking on the + button.
A cluster has advanced options, like:
- Lease – a user can specify when the servers in this cluster expire so that DCHQ can automatically destroy those servers. Placement Policy – a user can select from a number of placement policies like a proximity-based policy, round robin, or the default policy, which is a capacity-based placement policy that will place the Docker workload on the host that has sufficient compute resources.
- Networking – a user can select either Docker networking or Weave as a software-defined networking to facilitate cross-container communication across multiple hosts
- Quota – a user can indicate whether or not this cluster adheres to the quota profiles that are assigned to users and groups. For example, in DCHQ.io, all users are assigned a quota of 8GB of Memory.
- Auto-Scale Policy – a user can define an auto-scale policy to automatically add servers if the cluster runs out of compute resources to meet the developer’s demands for new container-based application deployments
- Granular Access Controls – a tenant admin can define access controls to a cluster to dictate who is able to deploy Docker applications to it through Entitled Users. For example, a developer may register his/her local machine and mark it as private. A tenant admin, on the other hand, may share a cluster with a specific group of users or with all tenant users. Additionally, the cluster owner can specify what application templates can be deployed to this cluster through Entitled Blueprints. If the cluster will be used in upstream environments, then only specific application templates (or “blueprints”) can be deployed on it.
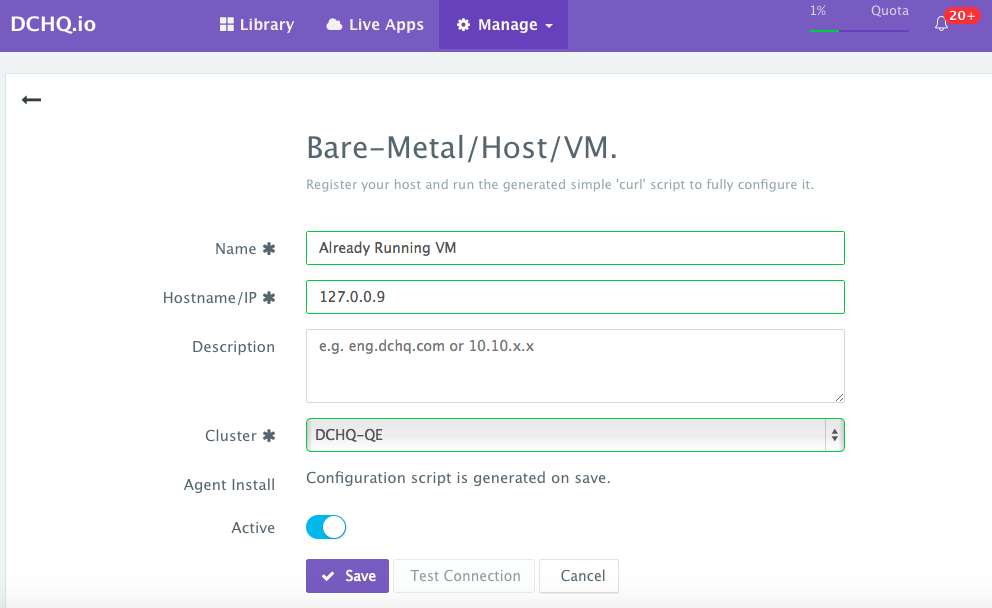
Register an already running virtual machine — A user can register an already running Microsoft Azure Virtual Machine. This can be done by navigating to Manage > Machines and then clicking on the + button. A user can then select the “VM/Bare-Metal” workflow and complete the required fields.
- Name — the name of the server you would like to register. This does not necessarily need to be the actual hostname.
- IP Address — this is the IP address of the server you’re registering.
- Cluster — this the cluster that the new server will be part of. Make sure that you create the cluster first — before registering servers or provisioning new ones.
Automate the provisioning of Docker-enabled Microsoft Azure virtual machines — A user can provision Microsoft Azure Virtual Machines on the newly created cluster either through a UI-based workflow or by defining a simple YAML-based Machine Compose template that can be requested from the Self-Service Library. The recommended approach is the Machine Compose template as it provides more security & standardization.
UI-based Workflow – A user can request a Microsoft Azure Virtual Machine by navigating to Manage > Machines and then clicking on the + button to select Microsoft Azure. Once the Cloud Provider is selected, a user can select the region, instance type, and image needed. A Cluster is then selected and the number of Microsoft Azure Virtual Machines can be specified.
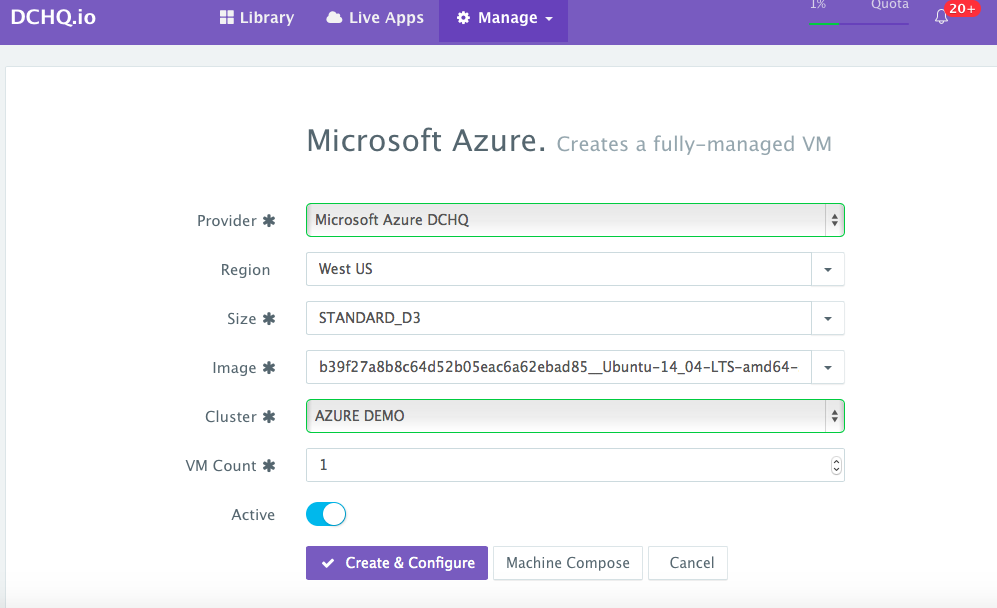
A user can then click on the Machine Compose button to generate a YAML-based Machine Compose template. This can be used to create your own standard Machine Compose template that can be shared with other users with granular access controls.
YAML-based Machine Compose Template (Recommended) – A user can create a Machine Compose template for Microsoft Azure by navigating to Manage > App/Machine and then clicking on the + button to select Machine Compose.
Here’s the template for requesting a D3 Microsoft Azure Virtual Machine in the West US region.
Machine: # Note: Some of the fields are optional based on provider and can be left empty. region: West US description: This provisions a Docker-enabled Standard D2 virtual machine in West US. instanceType: STANDARD_D3 image: b39f27a8b8c64d52b05eac6a62ebad85__Ubuntu-14_04-LTS-amd64-server-20140416.1-en-us-30GB/West US count: 1
The supported parameters for the Machine Compose template are summarized below:
- description: Description of the blueprint/template
- subnet: Cloud provider specific value (e.g. subnet ID for AWS)
- dataCenter — Cloud provider specific value (this is only needed for vSphere if you’re cloning from a VM Template and not a stopped VM)
- instanceType: Cloud provider specific value (e.g. general1-4)
- region: Cloud provider specific value (e.g. IAD)
- image: Mandatory – fully qualified image ID/name (e.g. IAD/5ed162cc-b4eb-4371-b24a-a0ae73376c73 or vSphere VM Template name)
- username: This the username used to connect to the server
- password: This can reference a private key stored in the Credentials store. The ID of the credential item stored in the Manage > Cloud Providers page will be needed. Here’s the acceptable format: “{{credentials | 2c91802a520736224015209a6393098322}}”
- network: Optional – Cloud provider specific value (e.g. default)
- securityGroup: Cloud provider specific value (e.g. dchq-security-group)
- keyPair: Cloud provider specific value (e.g. private key name)
- openPorts: Optional – comma separated port values
- count: Total no of VM’s, defaults to 1.
In addition to these supported parameters, a plugin can be invoked as follows:
plugins:
- !plugin
id: <plugin-id>The plug-in can be created by Navigating to Manage > Plugins and then clicking on the + button. A plug-in is a simple script that can run on either the server being provisioned or on the Docker container. The server plugins can be used for any number of configuration requirements:
- Installing Puppet Modules, Chef Recipes, Ansible Playbook, etc.
- Retrieving the CA certificate needed for the private Docker registry from a secure storage and then saving it in the right directory (e.g. /etc/docker/certs.d/:5000/ca.crt)
The Machine Compose template has additional advanced options.
- Cost Profiles — these are the cost profiles that you can create under Manage > Cost Profiles. You can define cost per resource on an hourly/weekly/monthly basis. You can attach multiple cost profiles to a single template — e.g. different cost profiles for the instance type, EBS storage used, etc.
- Entitled Users — these are the users who are allowed to use this template to provision virtual machines. The entitled users do not have permission to manage or delete this template and will only be able to consume it.
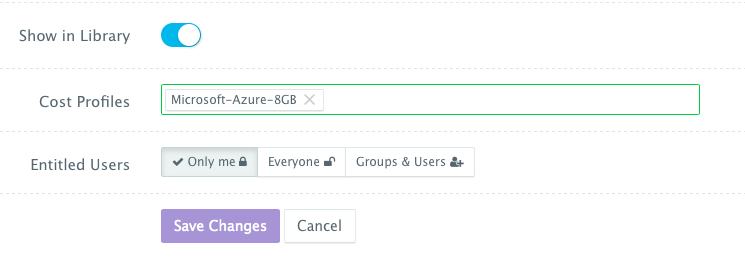
Once the Machine Compose template is saved, a user can request this machine from the Self-Service Library. A user can click Customize and then select the Cloud Provider and Cluster to use for provisioning these Microsoft Azure Virtual Machine(s).
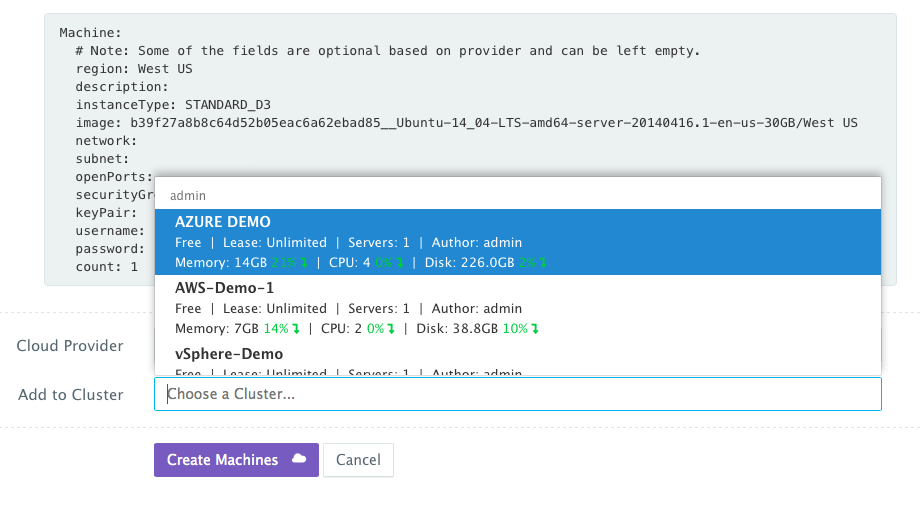
Deploying the Distributed, Highly Available Applications on the Microsoft Azure Cluster
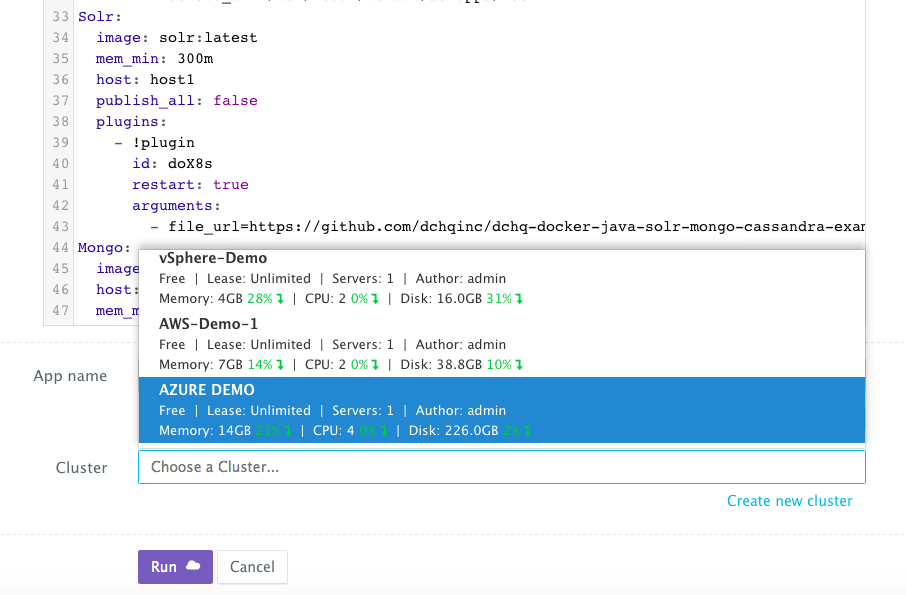
Once the Virtual Machines are provisioned, a user can deploy a multi-tier, Docker-based applications on the new Virtual Machines. This can be done by navigating to the Self-Service Library and then clicking on Customize to request a multi-tier application.
A user can select an Environment Tag (like DEV or QE) and the Docker-enabled Microsoft Azure Cluster created before clicking on Run.
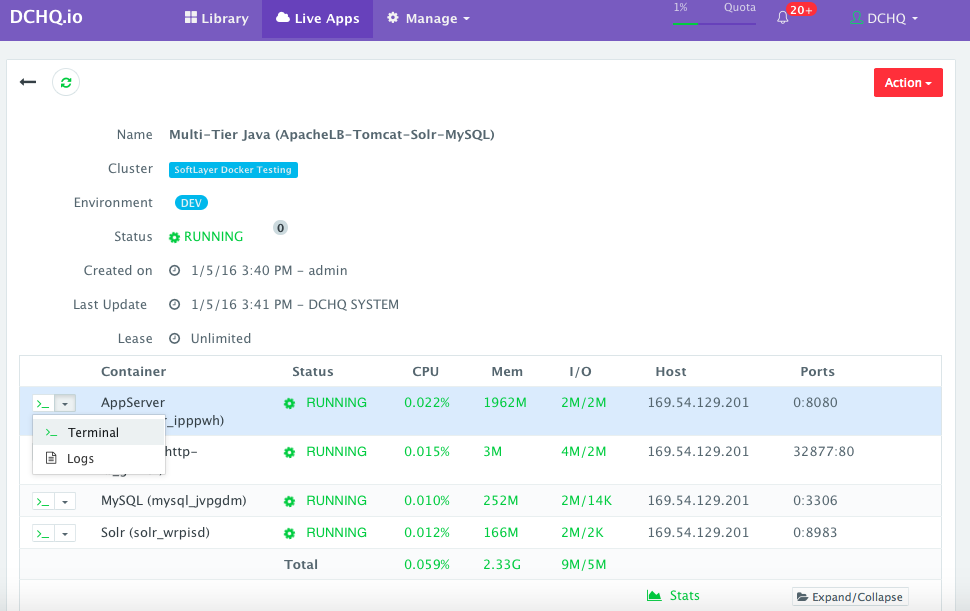
Accessing The In-Browser Terminal For The Running Containers
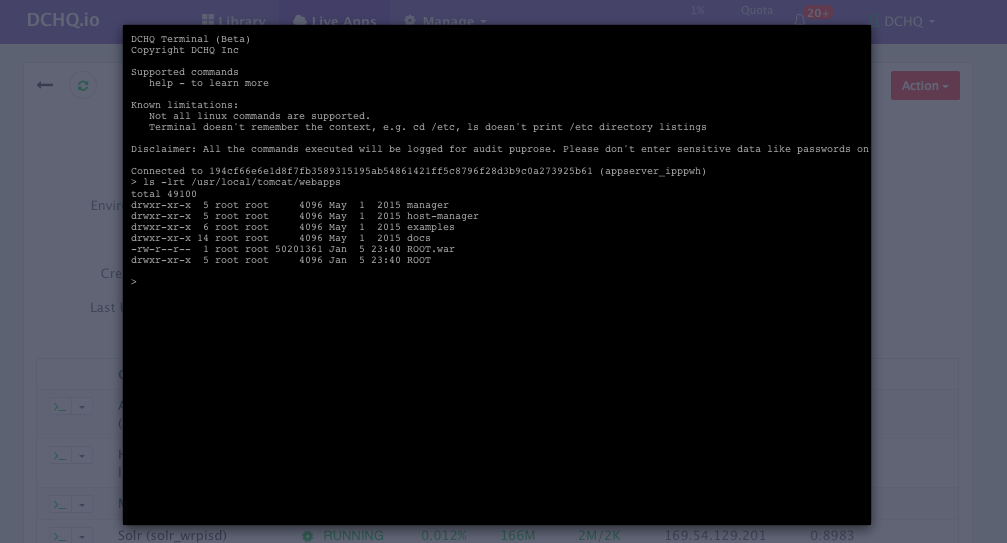
A command prompt icon should be available next to the containers’ names on the Live Apps page. This allows users to enter the container using a secure communication protocol through the agent message queue. A white list of commands can be defined by the Tenant Admin to ensure that users do not make any harmful changes on the running containers.
For the Tomcat deployment for example, we used the command prompt to make sure that the Java WAR file was deployed under the /usr/local/tomcat/webapps/ directory.
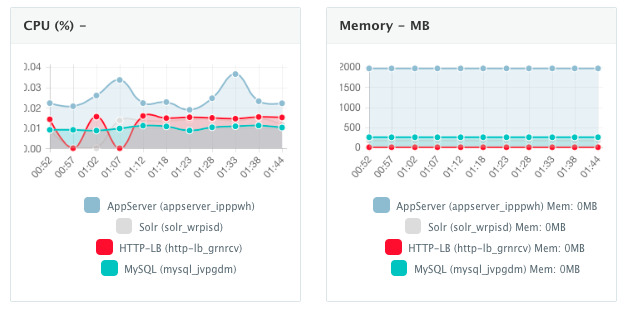
Monitoring the CPU, Memory & I/O Utilization of the Running Containers
Once the application is up and running, our developers monitor the CPU, Memory, & I/O of the running containers to get alerts when these metrics exceed a pre-defined threshold. This is especially useful when our developers are performing functional & load testing.
A user can perform historical monitoring analysis and correlate issues to container updates or build deployments. This can be done by clicking on the Stats menu of the running application. A custom date range can be selected to view CPU, Memory and I/O historically.
Scaling out the Tomcat Application Server Cluster
If the running application becomes resource constrained, a user can scale out the application to meet the increasing load. Moreover, a user can schedule the scale out during business hours and the scale in during weekends for example.
To scale out the cluster of Tomcat servers that is load balanced by Apache HTTP Server from 1 to 2, a user can click on the Actions menu of the running application and then select Scale Out. A user can then specify the new size for the cluster and then click on Run Now.
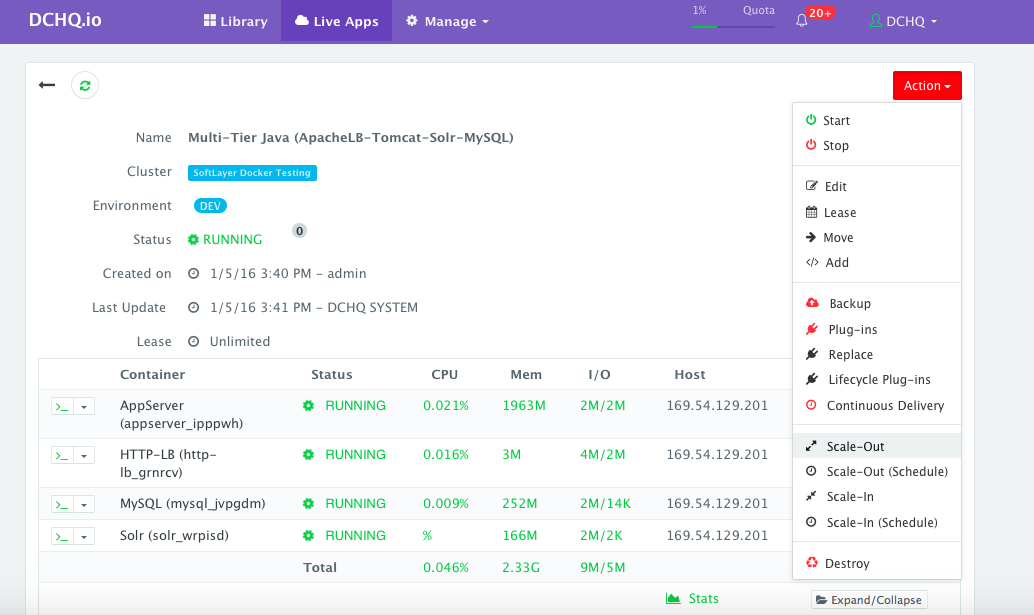
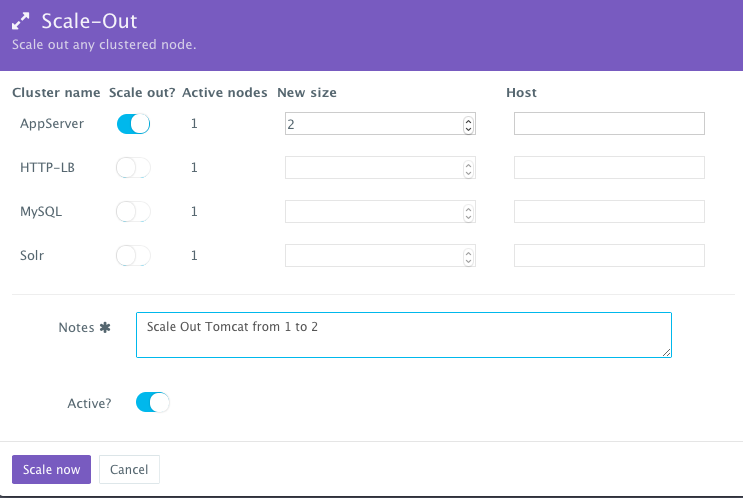
As the scale out is executed, the Service Discovery framework will be used to update the load balancer. A plug-in will automatically be executed on Apache HTTP Server to update Apache HTTP Server’s httpd.conf file so that it’s aware of the new application server added. This is because we have specified post_scale_out:AppServer as the lifecycle event for this plugin.
HTTP-LB:
image: httpd:latest
publish_all: true
mem_min: 50m
host: host1
plugins:
- !plugin
id: uazUi
restart: true
lifecycle: on_create, post_scale_out:AppServer, post_scale_in:AppServer
arguments:
# Use container_private_ip if you're using Docker networking
- BalancerMembers=BalancerMember http://{{AppServer | container_private_ip}}:8080
# Use container_hostname if you're using Weave networking
#- BalancerMembers=BalancerMember http://{{AppServer | container_hostname}}:8080
AppServer:
image: tomcat:8.0.21-jre8
mem_min: 600m
host: host1
cluster_size: 1
environment:
- mongo_url={{Mongo|container_private_ip}}:27017/dchq
- solr_host={{Solr|container_private_ip}}
- solr_port=8983
plugins:
- !plugin
id: oncXN
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-solr-mongo-cassandra-example/raw/master/dbconnect.war
- dir=/usr/local/tomcat/webapps/ROOT.war
- delete_dir=/usr/local/tomcat/webapps/ROOT
Solr:
image: solr:latest
mem_min: 300m
host: host1
publish_all: false
plugins:
- !plugin
id: doX8s
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-solr-mongo-cassandra-example/raw/master/names.zip
Mongo:
image: mongo:latest
host: host1
mem_min: 400mSimilarly, a scale out can be executed on a cluster of Tomcat Servers load balanced by Nginx. The Service Discovery framework will be used to update the load balancer. A plug-in will automatically be executed on Nginx to update Nginx’s default.conf file so that it’s aware of the new application server added. This is because we have specified post_scale_out:AppServer as the lifecycle event for this plugin.
Nginx:
image: nginx:latest
publish_all: true
mem_min: 50m
host: host1
plugins:
- !plugin
id: 0H1Nk
restart: true
lifecycle: on_create, post_scale_out:AppServer, post_scale_in:AppServer
arguments:
# Use container_private_ip if you're using Docker networking
- servers=server {{AppServer | container_private_ip}}:8080;
# Use container_hostname if you're using Weave networking
#- servers=server {{AppServer | container_hostname}}:8080;
AppServer:
image: tomcat:8.0.21-jre8
mem_min: 600m
host: host1
cluster_size: 1
environment:
- database_driverClassName=com.mysql.jdbc.Driver
- database_url=jdbc:mysql://{{MySQL|container_hostname}}:3306/{{MySQL|MYSQL_DATABASE}}
- database_username={{MySQL|MYSQL_USER}}
- database_password={{MySQL|MYSQL_ROOT_PASSWORD}}
- solr_host={{Solr|container_private_ip}}
- solr_port=8983
plugins:
- !plugin
id: oncXN
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-solr-mongo-cassandra-example/raw/master/dbconnect.war
- dir=/usr/local/tomcat/webapps/ROOT.war
- delete_dir=/usr/local/tomcat/webapps/ROOT
Solr:
image: solr:latest
mem_min: 300m
host: host1
publish_all: false
plugins:
- !plugin
id: doX8s
restart: true
arguments:
- file_url=https://github.com/dchqinc/dchq-docker-java-solr-mongo-cassandra-example/raw/master/names.zip
MySQL:
image: mysql:latest
host: host1
mem_min: 400m
environment:
- MYSQL_USER=root
- MYSQL_DATABASE=names
- MYSQL_ROOT_PASSWORD={{alphanumeric|8}}An application time-line is available to track every change made to the application for auditing and diagnostics. This can be accessed from the expandable menu at the bottom of the page of a running application. In this case, the Service Discovery framework executed the Apache HTTP Server plugin automatically right after the Application Server cluster was scaled out.
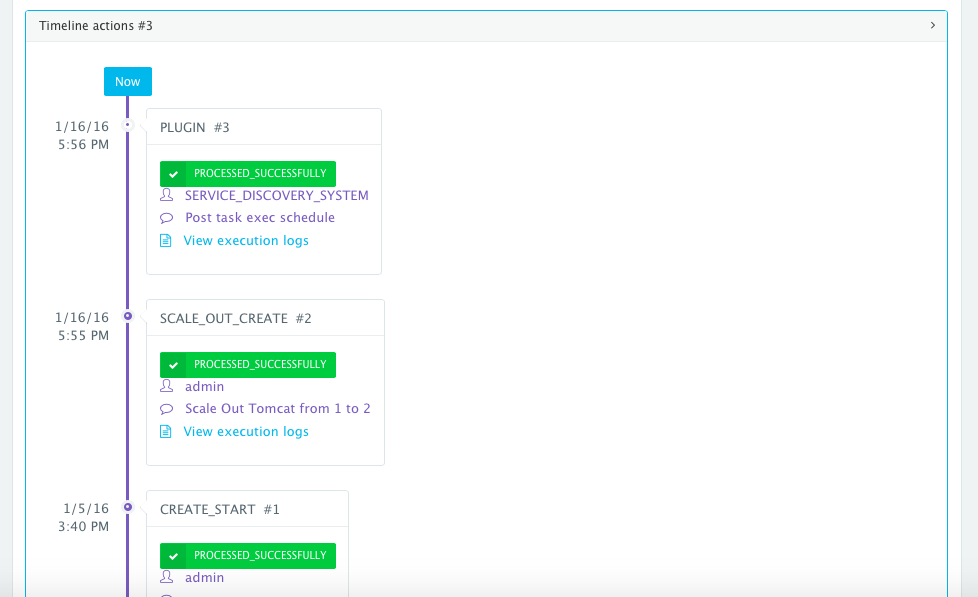
Alerts and notifications are available for when containers or hosts are down or when the CPU & Memory Utilization of either hosts or containers exceed a defined threshold.
Scaling out the Mongo Replica Set Cluster
If the running Mongo Replica Set becomes resource constrained, a user can scale it out to meet the increasing load. Moreover, a user can schedule the scale out during business hours and the scale in during weekends for example.
To scale out the Mongo Replica Set from 2 to 3, a user can click on the Actions menu of the running application and then select Scale Out. A user can then specify the new size for the cluster and then click on Run Now.
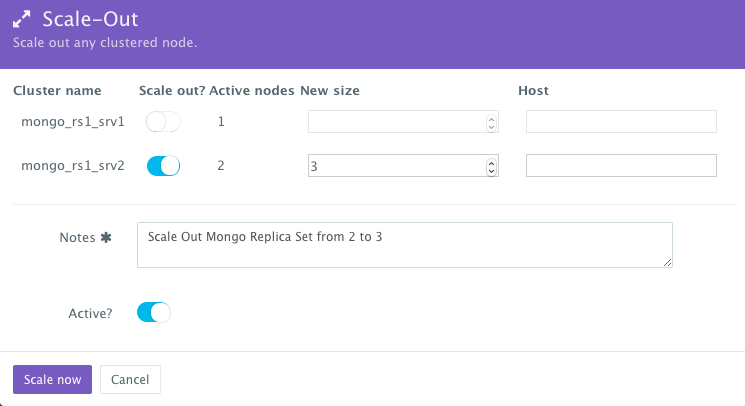
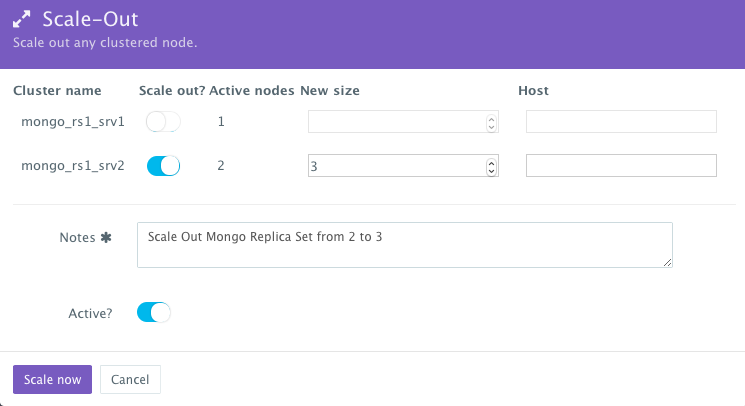
As the scale out is executed, the Service Discovery framework will be used to update the primary node Mongo container. A plug-in will automatically be executed on the primary node Mongo container to update rebalance the Replica Set so that it’s aware of the new secondary node Mongo containers added. This is because we have specified post_scale_out:mongo_rs1_srv2 as the lifecycle event for this plugin.
An application time-line is available to track every change made to the application for auditing and diagnostics. This can be accessed from the expandable menu at the bottom of the page of a running application. In this case, the Service Discovery framework executed the Mongo Replica Set plugin automatically right after the Application Server cluster was scaled out.
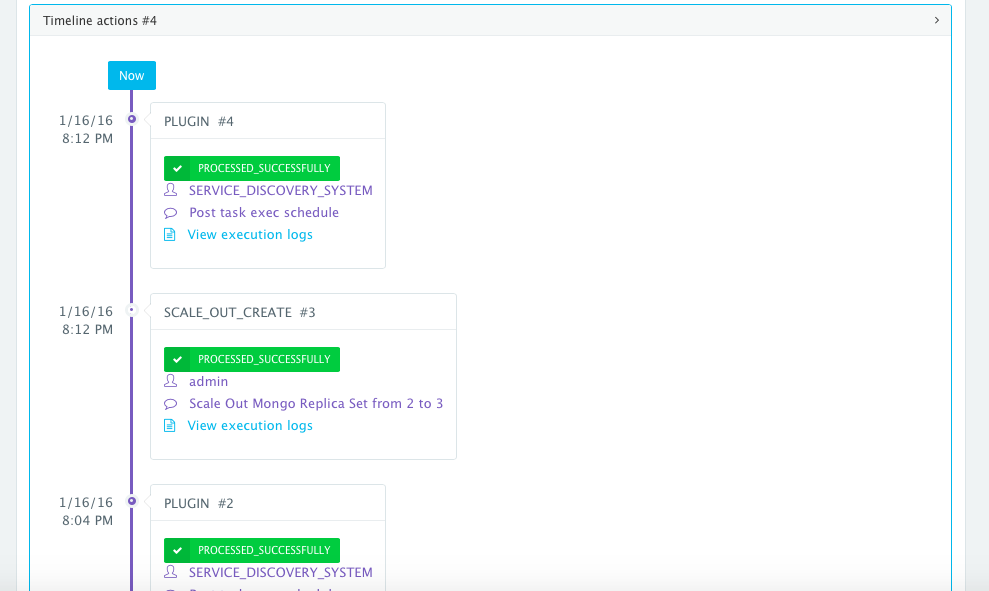
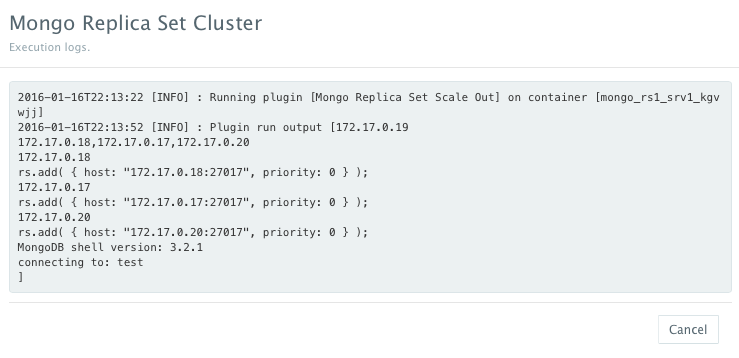
Scaling out the Hazelcast Cluster
If the running Hazelcast cluster becomes resource constrained, a user can scale out the cluster to meet the increasing load. Moreover, a user can schedule the scale out during business hours and the scale in during weekends for example.
To scale out the Hazelcast cluster from 1 to 2, a user can click on the Actions menu of the running application and then select Scale Out. A user can then specify the new size for the cluster and then click on Run Now.
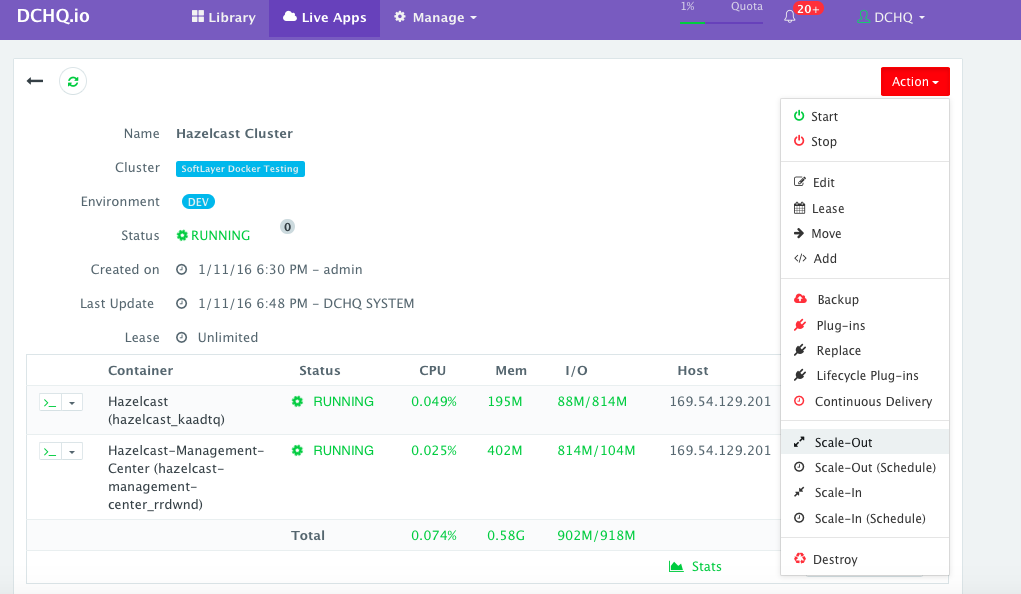
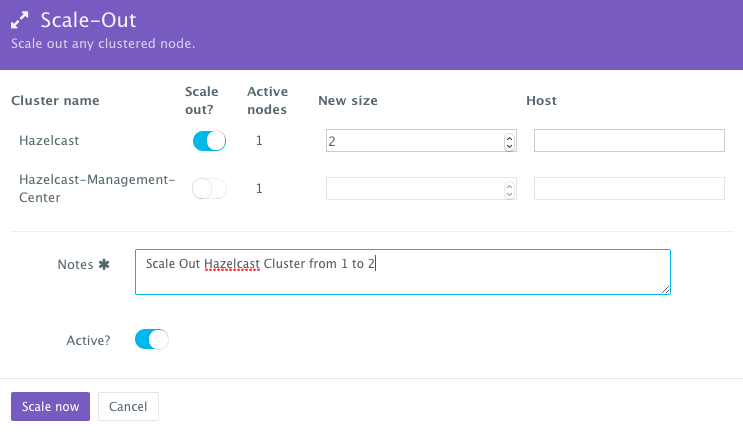
As the scale out is executed, the Service Discovery framework will be used to update the Hazelcast containers. A plug-in will automatically be executed on the Hazelcast containers to update the hazelcast.xml file so that it’s aware of the new Hazelcast containers added. This is because we have specified post_scale_out:Hazelcast as the lifecycle event for this plugin.
Hazelcast-Management-Center:
image: hazelcast/management-center:latest
# Use this configuration if deploying to a shared VM
publish_all: true
# (Recommended) Use this configuration if deploying to a dedicated VM
#ports:
# - 8080:8080
host: host1
environment:
- HAZELCAST_IP={{Hazelcast | container_private_ip}}
Hazelcast:
image: hazelcast/hazelcast:latest
# Use this configuration if deploying to a shared VM
publish_all: true
# (Recommended) Use this configuration if deploying to a dedicated VM
#ports:
# - 5701:5701
cluster_size: 1
host: host1
plugins:
- !plugin
id: Qgp4H
lifecycle: post_create, post_scale_out:Hazelcast, post_scale_in:Hazelcast
restart: true
arguments:
# Use this configuration if deploying to a shared VM
- Hazelcast_IP=<member>{{Hazelcast | container_private_ip}}</member>
# (Recommended) Use this configuration if deplying to a dedicated VM
#- Hazelcast_IP=<member>{{Hazelcast | ip}}</member>
- Management_Center_URL=http://{{Hazelcast-Management-Center | ip}}:{{Hazelcast-Management-Center | port_8080}}/mancenter
environment:
# Uncomment the line below to specify the heap size
#- MIN_HEAP_SIZE="1g"
# Uncomment the line below to provide your own hazelcast.xml file
- JAVA_OPTS=-Dhazelcast.config=/opt/hazelcast/hazelcast.xml
volumes:
# Uncomment the line below if you plan to use your own hazelcast.xml file
#- ./configFolder:./configFolderAn application time-line is available to track every change made to the application for auditing and diagnostics. This can be accessed from the expandable menu at the bottom of the page of a running application. In this case, the Service Discovery framework executed the Hazelcast plugin automatically right after the Hazelcast cluster was scaled out.
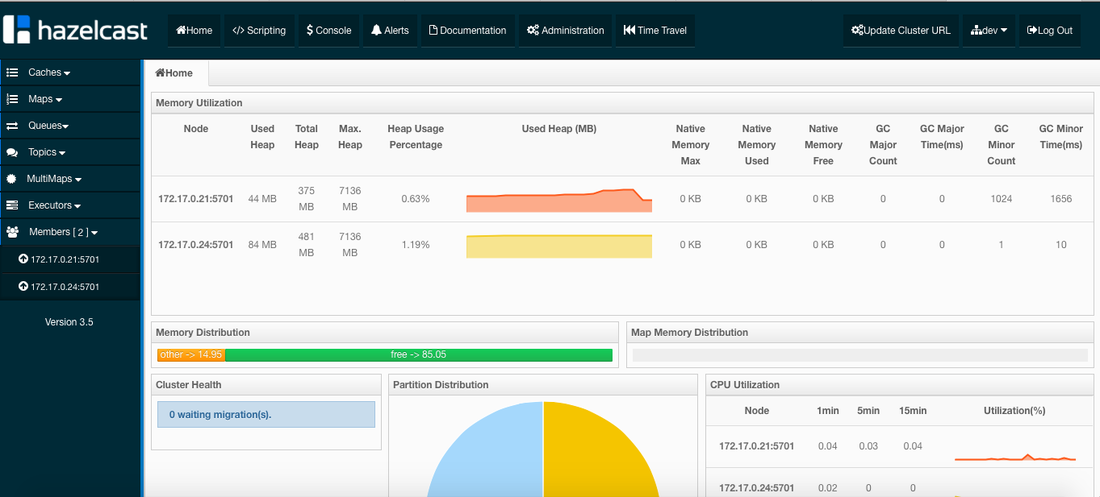
Alerts and notifications are available for when containers or hosts are down or when the CPU & Memory Utilization of either hosts or containers exceed a defined threshold.
Conclusion
Containerizing enterprise Java applications is still a challenge mostly because existing application composition frameworks do not address complex dependencies, service discovery or auto-scaling workflows post-provision.
DCHQ, available in hosted and on-premise versions, addresses all of these challenges and simplifies the containerization of enterprise applications through an advance application composition framework that facilitates cross-image environment variable bindings, extensible BASH script plug-ins that can be invoked at different life-cycle stages for service discovery, and application clustering for high availability across multiple hosts or regions with support for auto scaling.
Sign Up for FREE on http://DCHQ.io or download DCHQ On-Premise to get access to out-of-box multi-tier enterprise application templates along with application lifecycle management functionality like monitoring, container updates, scale in/out and continuous delivery.
