One of the headaches of web programming has been the storage and retrieval of user data within an application. Imagine having a database in the server side for storing, for example, some user preferences. That would be a complete overkill, because our web application may not need a server.
HTML5 introduced the IndexedDB technology, a persistent client-side data storage, per each domain. This means that an HTML5 application is able to work with a database (using the JavaScript API) without the need of having any server.
IndexedDB was introduced by the W3C for replacing the deprecated WebSQL, so, if you have ever used this last one, or at least thinking about it, you should dismiss this idea and have a look to the IndexedDB.

For this example, the following browsers have been used for testing:
- Chromium 56.0.2924.76.
- Firefox 52.0.1.
- Opera 44.0.
1. Difference between IndexedDB and LocalStorage
If you have already dealt with client side storage, you may know LocalStorage. At first, it may result confusing for the user to choose between LocalStorage and IndexedDB, because, at a first glance, they may be used for the same purpose: storing data in the client side, in a persistent way. So, we should leave clear the difference between this two technologies, in order to be able to make the most suitable decision for our application when we have to choose a client side storage technology.
The most important difference between LocalStorage and IndexedDB, is that the first one is for storing data in string format in key-value format, and with the second one we can store whole objects in object stores. So, for LocalStorage, we can think about an embedded table with two columns, one for the id and the other for the value in string format; and, for IndexedDB, engine that allows us to have several tables (object stores, as mentioned before) among several databases. Taking this into account, we could say that IndexedDB would be more suitable for more complex data structures, since we can define several storages for several databases (and for several versions of databases) where we can store JavaScript objects; and LocalStorage for the simplest data storage possible in string format (note that the option of stringifying the objects also exists).
There are other differences in the API between these two technologies that of course would affect to the implementation of our applications in one way or another. But the difference we talked about should be the only one to take into account at the time of choosing a technology for storing data in the client side.
2. Some features of IndexedDB
Before we start coding, it’s worth talking about the features of IndexedDB. Otherwise we may get lost just after diving into the code.
IndexedDB allows several databases and several storages for each one
We have already mentioned this in the previous section. We can have as many databases as we want, and the same with storages for each database. Each database, apart from its name, it also has a version number that identifies it. Every time we want to alter the structure of our database, we have to upgrade the database version.
For obvious reasons, each database belongs just to the domain it was created for.
IndexedDB is NOT SQL
This is not actually a feature itself, but is something that must be mentioned to avoid usual misconceptions. IndexedDB is not an SQL database. We are not going to define structures like we would do for an SQL database. In any case, the most suitable analogy would be with NoSQL databases.
IndexedDB API is asynchronous
This is the most important feature of IndexedDB. This means that the request to the IndexedDB for opening a database is non blocking. Let’s see with a simple piece of code:
request = indexedDB.open('database');
database = request.result;Wouldn’t be valid. We can’t use the IndexedDB in that way. Instead, we would have to do the following:
request = indexedDB.open('database');
request.onsuccess = function() {
database = request.result;
// Now we can perform database operations.
}3. Usage
Now that we have clear the concepts of IndexedDB, we will see it in usage.
3.1. Creating the database
The first thing we have to do is retrieve the IndexedDB object, and then perform a request for opening a database of a given name and version (the version is optional).
For this example, we will suppose that we have a database for a catalog of products, for which we will save information such as name, description, price, etc.
indexeddb.js
DATABASE_NAME = 'catalog';
DATABASE_VERSION = 1;
STORE_NAME = 'product';
var database;
var indexedDB = window.indexedDB || window.webkitIndexedDB
|| window.mozIndexedBD || window.msIndexedDB;
var request = indexedDB.open(DATABASE_NAME, DATABASE_VERSION);Note that, for getting the indexedDB object, we set several fallbacks, each one for each browser engine.
The first we should do after requesting a database, is to bind a function to the onupgradeneeded event. This will be called on database creation, or on version upgrade.
indexeddb.js
request.onupgradeneeded = function() {
console.log('Database upgrade/creation.');
database = request.result;
var catalogStore = database.createObjectStore(
STORE_NAME,
{
keyPath: 'id',
autoIncrement: 'true'
}
);
catalogStore.createIndex('by_id', 'id');
catalogStore.createIndex('by_name', 'name');
console.log('The database has been created/updated.');
}The first thing we do here is to retrieve the database itself, which is the result attribute of the request object retrieved from the IndexedDB object.
Then, we create the store for the catalog, with the createObjectStore method. The first parameter, the name of the store, is mandatory, but not the second one, the options. In this case, we used the two available options:
keyPath: this would the “primary key” of the storage.autoIncrement: this property is for making the key path property increment automatically for each new inserted object, so we don’t have to care about giving it a value.
Even if we already defined a primary key, we can create and index for it so we can access it by its index, and also for any other property of the object. In this case, we have created for both name and id properties, with the createIndex method. The first parameter is the name of the index itself, which is later needed when retrieving the data, since we need to specify which index we are using; and the second parameter is the property it corresponds to.
All this is will be executed once, unless we change the database version.
3.2. Inserting data
We can insert data into the database on creation time, or later. If we do it inside the onupgradeneeded scope, we don’t have to explicitly declare a transaction.
indexeddb.js
function insertInitialData(catalogStore) {
catalogStore.put({
'name': 'A product',
'description': 'Description of a product.',
'price': 10,
});
catalogStore.put({
'name': 'Another product',
'description': 'Description of another product.',
'price': 20,
'subproduct': {
'name': 'Subproduct of a product'
}
});
}
request.onupgradeneeded = function() {
// After creating the object storage and indexes...
insertInitialData(catalogStorage);
// ...
}Note that we are just inserting raw objects, which have properties that have not been even specified in the storage definition. If you have just used SQL databases, this may be quite confusing. But, yes, we can insert objects without taking care of which properties they have. We can even nest objects, as with the second product.
If we have a look to the database with the developer tools, we can see its data and structure. The following image shows the database and data we have defined above, using the Chromium developer tools.
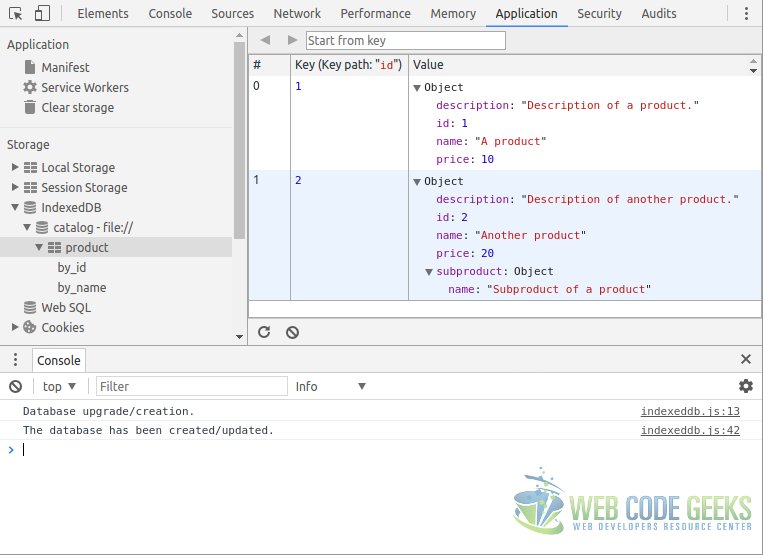
Note: the value shown in the column with the hashtag is just an enumeration made by the developer tools, it’s not a stored value.
If we want to insert data after the creation, we have to do it outside the onupgradeneeded scope. There’s another event available, onsuccess, that is triggered after a successful database creation/upgrade. We will insert some data here:
indexeddb.js
request.onsuccess = function() {
console.log('Successful request for IndexedDB.');
database = request.result;
var transaction = database.transaction(STORE_NAME, 'readwrite');
var catalogStore = transaction.objectStore(STORE_NAME);
var moreData = [
{
'name': 'A third product',
'description': 'Description of a third product.'
},
{
'name': 'Yet another product',
'description': 'One last product.'
}
];
moreData.forEach(function(data) {
catalogStore.put(data);
});
transaction.oncomplete = function() {
console.log('Transaction completed successfully.');
}
transaction.onerror = function(error) {
console.log('An error occurred during the transaction: ' + error);
}
}Look carefully at the code. First of all, we have to know that this listener is set for the open method call on indexedDB object. This event will be fired every time, not like onupgradeneeded.
After getting the database from the request, first, we create a transaction for the given store (we only have one, product) that must exist in the database. As we are going to insert data, the transaction has to provide write access, which is achieved passing the 'readwrite' value as second parameter.
From this transaction, we get the storage object, for which we will use the put method for inserting the data, as we did before. In this case, we have defined an array of objects and iterated it for inserting each one in the database, but is the same as we did before, just calling the put method for every object.
We can also define handlers for the success, or failure, of the transaction, defining functions for the oncomplete and the onerror events.
Take into account that we are inserting several objects for a single transaction. This means that, if a insertion for some of the objects fails, for any reason, a rollback will be made to the state previous to the transaction init. In other words: in an error occurs, the transaction will end with no data inserted, even if it happened for a single object, and other objects could be successfully inserted.
3.3. Retrieving data
Of course, we will also see how to retrieve the data.
The initial steps for retrieving data are the same as what we made for inserting it: first, we create a transaction (it’s necessary also even for read only operations), and we get the storage from it.
Having the storage, we can proceed to the retrieval of the information. For it, we have to get the indexes of the fields we want to make “query” for, and then make the request to this index.
Let’s see a function for querying some data:
indexeddb.js
function query() {
var transaction = database.transaction(STORE_NAME, 'readonly');
var catalogStore = transaction.objectStore(STORE_NAME);
var idIndex = catalogStore.index('by_id');
var nameIndex = catalogStore.index('by_name');
var request = idIndex.get(1);
request.onsuccess = function() {
console.log(request.result);
}
var request2 = nameIndex.get('Another product');
request2.onsuccess = function() {
console.log(request2.result);
}
}As we can see, we have made different requests on different indexes, just to see that we can used any of the defined indexes. For this, we also have to use the onsuccess event, because, remember, the API is asynchronous.
Because of this reason, we have to create another request after the first one, request2. If we would use the first request object, we would get a “The request has not finished” exception.
The results shown in the console would the the following ones:
Object {
name: "A product",
description: "Description of a product.",
price: 10,
id: 1
}
Object {
name: "Another product",
description: "Description of another product.",
price: 20,
subproduct: Object,
id: 2
}3.4. Cursors
Yes! IndexedDB also supports cursors. And they are very easy. For example, the following function would show all the elements of the storage:
indexeddb.js
function queryWithCursor() {
var transaction = database.transaction(STORE_NAME, 'readonly');
var catalogStore = transaction.objectStore(STORE_NAME);
catalogStore.openCursor().onsuccess = function(event) {
var cursor = event.target.result;
if (cursor) {
console.log(cursor.value);
cursor.continue();
}
}
}4. Summary
This example has shown the usage of IndexedDB, the technology introduced with HTML5 for storing data in the client side. Actually, IndexedDB is not the only option for storing data in the client side, and that’s why we made a comparison with LocalStorage, the other feature introduced in HTML5, that may result similar at first sight, but which serve for different purposes. Finally, we have seen how to deal with the IndexedDB API, creating databases, inserting data, etc.
5. Download the source code
This was an example of HTML5 IndexedDB.
You can download the full source code of this example here: HTML5IndexedDBExample
