From release 2.6, MongoDB includes a new minDistance option for geospatial queries.
This is exciting because it lets you page through geospatial results very efficiently, and because it’s the first feature I’ve contributed to the database itself.
I’ll measure how minDistance performs and show you an example app.
Better, Faster
I’m going to fill a MongoDB collection with the locations of sidewalk cafés in NYC, and declare a 2dsphere index on those locations. In Python:
from pymongo import MongoClient
db = MongoClient().test
db.cafes.insert({
'Entity Name': 'Cafe Mocha, Inc.',
'Sidewalk Cafe Type': 'Unenclosed',
'Street Address': '116 2 Avenue',
'location': {
'type': 'Point',
'coordinates': [
-73.98817410082268,
40.72788705499784
],
}
})
db.cafes.create_index([
('location', '2dsphere')])I have info for 1008 cafés from NYC Open Data. Now I can query for the ten cafés nearest Union Square:
result = db.command(
'geoNear', 'cafes',
near={
'type': 'Point',
'coordinates': [
-73.991084,
40.735863]},
spherical=True,
num=10)MongoDB returns them to me sorted from nearest to farthest. The problems start if I want the next 10 results. MongoDB doesn’t support skip with geo queries. I can simulate it with the aggregation framework. I query for 20 cafés and filter out the first 10 with the aggregation framework’s $skip operator:
result = db.cafes.aggregate([{
'$geoNear': {
'near': {
'type': 'Point',
'coordinates': [
-73.991084,
40.735863]},
'spherical': True,
'distanceField': 'dist',
'num': 20}
}, {
'$skip': 10
}])This trick (from my colleague Asya Kamsky) lets me page through geo results, but it gets slower with bigger skip values. I timed it on a collection of 10,000 random locations:
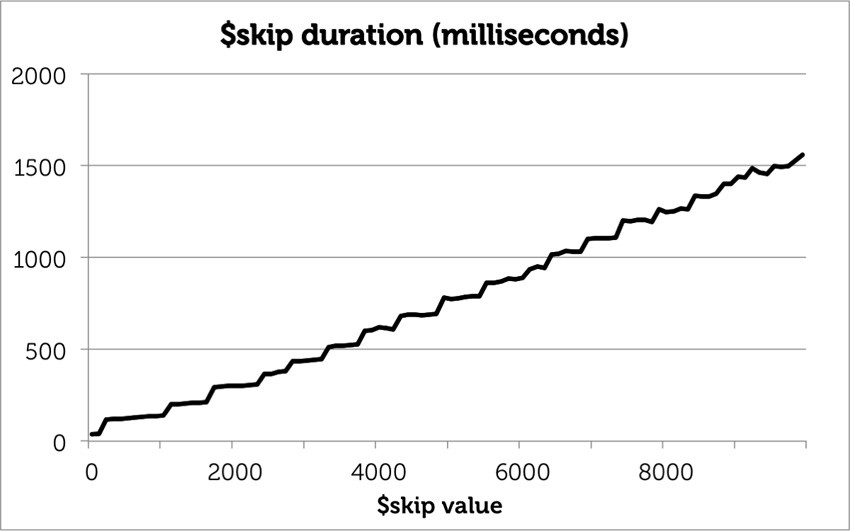
As the $skip number grows from zero to 10,000, the duration grows linearly, even though the query always returns 10 results. After all, in order to get those 10 documents, MongoDB must find all the prior documents and pass them through the aggregation pipeline, only to discard them at the $skip phase.
Paging through geo results is obviously useful, so how do we do it efficiently? MongoDB 2.6 comes with a new minDistance option for geospatial queries. This is my first contribution to MongoDB’s C++ code—generally I work on Python. Hold your applause, please: I just wired together some mechanisms built by minds greater than mine, and even so I needed a lot of handholding from Hari Khalsa. However simple the feature was to implement, it makes paging through geo results much faster.
Here’s how to page with minDistance. I query for the first 10 locations normally. When I want the next 10 locations, I set minDistance to the farthest distance I’ve seen so far. So if my 10th result is 268 meters away and has id 42:
{
'dis': 268,
'obj': {
'_id': 42,
'Entity Name': 'LM Restaurant Group',
'Street Address': '120 East 15 Street',
'location': {
'type': 'Point',
'coordinates': [
-73.98834760821919,
40.73463761939186
]
}
}
}… then I set minDistance to 268 and query for the next 10 documents. I must also exclude this document’s id to avoid seeing it again in the next batch, since minDistance is inclusive.
ids = [42]
result = db.command(
'geoNear', 'cafes',
near={
'type': 'Point',
'coordinates': [
-73.991084,
40.735863]},
spherical=True,
minDistance=268,
query={
'_id': {
'$nin': ids}},
num=10)The farthest document from the first batch is excluded using a “not in” ($nin) query. If several documents are equally far away, I’d exclude all their ids. This technique performs quite well on my random collection:
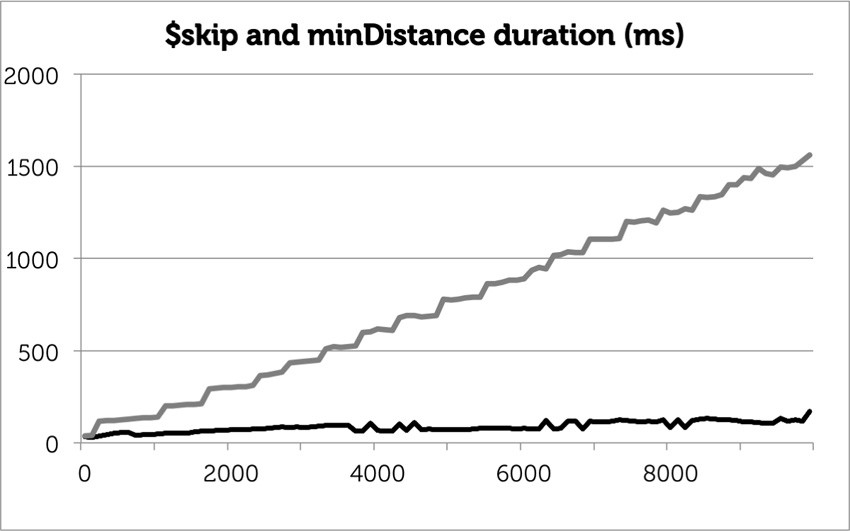
The first batch performs the same as it did with the aggregation framework, but the final batch takes one tenth the time with minDistance as it did with $skip: 170ms instead of 1.6 seconds.
An Example App
Paging with minDistance requires some futzy code, compared to the straightforward aggregation technique. To work out the kinks, I made an example app with my sidewalk-café data. You can play with it here:
The app uses PyMongo, Flask, and MongoDB. To start, enter a location dense with sidewalk cafés, like my zipcode “10009”. The app asks Google for the coordinates of your location, and shows you the 10 nearest cafés:
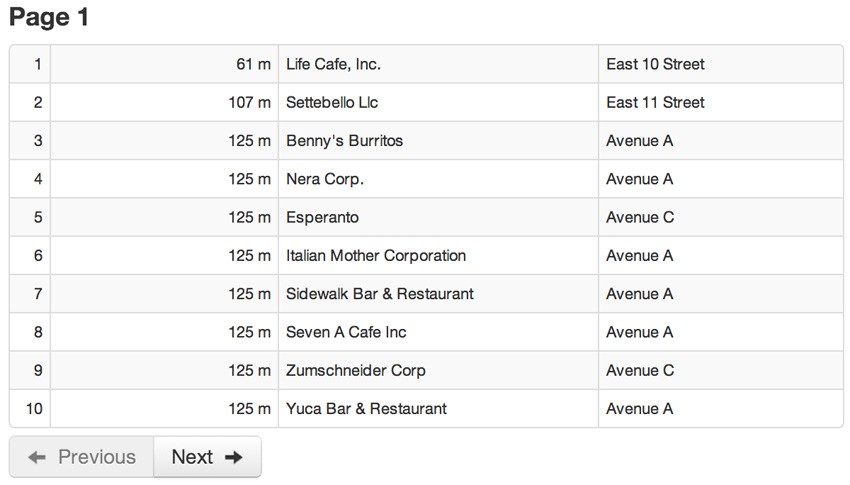
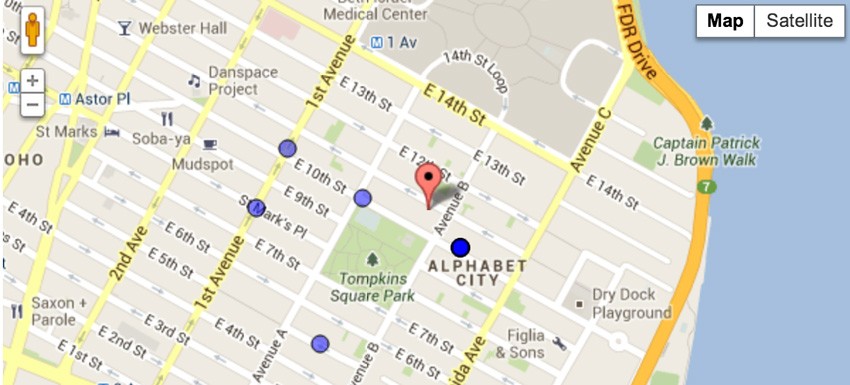
As you click Next, some Javascript asks the server-side application for the next 10 points. The script keeps track of the farthest distance it has seen so far, and passes that distance to the server when it asks for the next batch. You can see the ring of cafés move outwards from the center-point as minDistance increases.
When the script asks the server for the next batch, it also passes the ids of all documents at the current farthest distance, and the server excludes them. Normally this exclusion-list has just one id: the id of the last point retrieved. But the city’s data has some bugs. There are 14 cafés with the same geocoordinates, despite distinct addresses. Bruno The King Of Ravioli, for example, is twelve blocks from my beloved Benny’s Burritos, but they’re listed at the same (wrong) geocoordinates on 10th Street near Avenue B. Since they’re at the same coordinates, they have the same distance from your center point. Paging through such data using minDistance requires a careful algorithm. In pseudo-Python:
min_distance = 0
last_ids = []
def get_batch():
global min_distance, last_ids
result = db.command(
'geoNear', 'cafes',
near=center_point,
spherical=True,
minDistance=min_distance,
query={
'_id': {'$nin': last_ids}
},
num=10)
results = result['results']
if not results:
# Finished.
return []
# Last result is farthest.
new_min_distance = result[-1]['dis']
if new_min_distance == min_distance:
# We're still paging through results
# all at same distance as previous
# farthest. Append to last_ids.
last_ids += [
r['obj']['_id'] for r in results]
else:
# Results in this page are farther
# than previous page.
# Replace last_ids.
min_distance = new_min_distance
last_ids = [
r['obj']['_id']
for r in result['results']
if r['dis'] == min_distance]
return resultsThis takes care of paging forward from the nearest 10 cafés to the farthest. How do we go backwards? Unfortunately, the geoNear command doesn’t support searching inward from a maxDistance: it always iterates from near to far. My solution is simply to cache results as I retrieve them. So when you click Previous in my app, it shows you the previous page from the results it keeps in memory. If you hit Next again, the app checks whether it has the next page of results cached, and if so avoids the round trip to the server.
What’s Next?
Check out my application on GitHub; the most interesting code is the server-side results() function which runs the geoNear command, and the Javascript getMoreRows() function which implements the paging algorithm. Install the current production release of MongoDB, make something cool with geo data, and let me know.
| Reference: | Efficiently Paging Geospatial Data With MongoDB from our WCG partner Jesse Davis at the A. Jesse Jiryu Davis blog. |
