Over the weekend I wanted to look into the WordPress data behind this blog (very meta!) and wanted to get the data in CSV format so I could do some analysis in R.
I found a couple of WordPress CSV plugins but unfortunately I couldn’t get any of them to work and ended up working with the raw XML data that WordPress produces when you ‘export’ a blog.
I had the problem of the export being incomplete which I ‘solved’ by importing the posts in two parts of a few years each.
I then spent quite a few hours struggling to get the data into shape using R’s rvest library but eventually decided to do the scraping using Python’s beautifulsoup and save it to a CSV file for analysis in R.
The structure of the XML that we want to extract is as follows:
<rss version="2.0"
xmlns:excerpt="http://wordpress.org/export/1.2/excerpt/"
xmlns:content="http://purl.org/rss/1.0/modules/content/"
xmlns:wfw="http://wellformedweb.org/CommentAPI/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:wp="http://wordpress.org/export/1.2/"
>
...
<channel>
<item>
<title>First thoughts on Ruby...</title>
<link>http://www.markhneedham.com/blog/2006/08/29/first-thoughts-on-ruby/</link>
<pubDate>Tue, 29 Aug 2006 13:31:05 +0000</pubDate>
...
I wrote the following script to parse the files:
from bs4 import BeautifulSoup
from soupselect import select
from dateutil import parser
import csv
def read_page(page):
return BeautifulSoup(open(page, 'r').read())
with open("posts.csv", "w") as file:
writer = csv.writer(file, delimiter=",")
writer.writerow(["title", "date"])
for row in select(read_page("part2.xml"), "item"):
title = select(row, "title")[0].text.encode("utf-8")
date = parser.parse(select(row, "pubdate")[0].text)
writer.writerow([title, date])
for row in select(read_page("part1.xml"), "item"):
title = select(row, "title")[0].text.encode("utf-8")
date = parser.parse(select(row, "pubdate")[0].text)
writer.writerow([title, date])We end up with a CSV file that looks like this:
$ head -n 10 posts.csv title,date Functional C#: Writing a 'partition' function,2010-02-01 23:34:02+00:00 Coding: Wrapping/not wrapping 3rd party libraries and DSLs,2010-02-02 23:54:21+00:00 Functional C#: LINQ vs Method chaining,2010-02-05 18:06:28+00:00 F#: function keyword,2010-02-07 02:54:13+00:00 Willed vs Forced designs,2010-02-08 22:48:05+00:00 Functional C#: Extracting a higher order function with generics,2010-02-08 23:17:47+00:00 Javascript: File encoding when using string.replace,2010-02-10 00:02:02+00:00 F#: Inline functions and statically resolved type parameters,2010-02-10 23:06:14+00:00 Javascript: Passing functions around with call and apply,2010-02-12 20:18:02+00:00
Let’s quickly look over the data in R and check it’s being correctly exported:
require(dplyr)
require(lubridate)
df = read.csv("posts.csv")
> df %>% count()
Source: local data frame [1 x 1]
n
1 1501So we’ve exported 1501 posts. Let’s cross check with the WordPress dashboard:
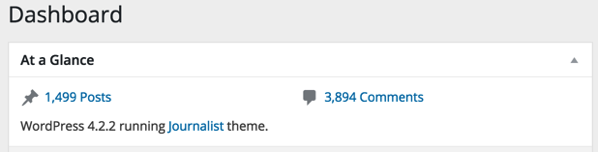
We’ve gained two extra posts! A bit more exploration of the WordPress dashboard reveals that there are actually 2 draft posts lying around.
We probably want to remove those from the export and luckily there’s a ‘status’ tag for each post that we can check. We want to make sure it doesn’t have the value ‘draft’:
from bs4 import BeautifulSoup
from soupselect import select
from dateutil import parser
import csv
def read_page(page):
return BeautifulSoup(open(page, 'r').read())
with open("posts.csv", "w") as file:
writer = csv.writer(file, delimiter=",")
writer.writerow(["title", "date"])
for row in select(read_page("part2.xml"), "item"):
if (not row.find("wp:status")) or row.find("wp:status").text != "draft":
title = select(row, "title")[0].text.encode("utf-8")
date = parser.parse(select(row, "pubdate")[0].text)
writer.writerow([title, date])
for row in select(read_page("part1.xml"), "item"):
if (not row.find("wp:status")) or row.find("wp:status").text != "draft":
title = select(row, "title")[0].text.encode("utf-8")
date = parser.parse(select(row, "pubdate")[0].text)
writer.writerow([title, date])I also had to check if that tag actually existed since there were a couple of posts which didn’t have it but had been published. If we check the resulting CSV file in R we can see that we’ve now got all the posts:
> df = read.csv("posts.csv")
> df %>% count()
Source: local data frame [1 x 1]
n
1 1499Now we’re ready to test a couple of hypotheses that I have but that’s for another post!
| Reference: | Python: Converting WordPress posts in CSV format from our WCG partner Mark Needham at the Mark Needham Blog blog. |
