You don’t need to be a logging expert to know that when it comes to logging in applications, there’s a wide variety of options to choose from.
There’s the Common Log Format, the Combined Log Format, and Nginx’s log format; and on and on the list goes.
But are any of these really the right choice? Honestly, what’s right and wrong is debatable. It’s something that varies from application to application. What’s more, each of the aforementioned formats, as well as the countless others, has its strengths and weaknesses. But are any of them the right one — at least for you?
Some formats allow for logs which contain copious amounts of information, but then they can turn into an unintelligible mess when it comes time to read them.
Others are simpler, yet don’t allow for as much information to be stored. You can be left without enough information when it comes time to parse them. Dumping a JSON object object can be a good thing, but it too has its drawbacks.
Wouldn’t it be great if there was one that was pretty easy to both read and write, both by humans and by computers? That sounds a little like a Holy Grail of sorts.
However, as part of an application I was developing lately, I came across a log format which, whilst not completely fitting the bill, still does a pretty good job of working for both humans and computers. It’s called logfmt.
What Is logfmt?
Logfmt, in essence, simply logs data as a series of one or more key/value pairs. No more, no less! This might seem simplistic, trivial even. But I find there’s a certain beauty both in the simplicity and flexibility of the format.
There aren’t a set of predefined options, such as in the Common Log Format, which are the only ones you’re able to use. Instead, you’re able to specify exactly what your application needs on a case-by-case basis.
This is great — you’re able to create log entries to suit specifically what you’re doing. Then, regardless of what’s logged, the format’s always the same. This makes it simpler to create parsers for the information stored.
Let’s look at a simple, concrete example so you can see what it looks like and how to get started. Specifically, I’m using the Express framework for Node.js. This example isn’t the most sophisticated, but it shows a good example of using the library.
var express = require('express');
var logfmt = require('logfmt');
var app = express();
function getSomeEnvironmentData(req, res)
{
return {
baseUrl: req.baseUrl,
hostname: req.hostname,
protocol: req.protocol,
name: req.params.name
} ;
}
app.get('/', function (req, res) {
console.log(logfmt.stringify(getSomeEnvironmentData(req, res)))
res.send('Hello World!');
});
app.get('/:name', function (req, res) {
console.log(logfmt.stringify(getSomeEnvironmentData(req, res)))
res.send('Hello World, ' + req.params.name);
});
var server = app.listen(3000, function () {
var host = server.address().address;
var port = server.address().port;
console.log('Example app listening at http://%s:%s', host, port);
});Here I’ve written a simple function, getSomeEnvironmentData(), which takes the request and response objects and composes a user-defined object that stores the baseUrl, hostname, request protocol, and the value of the :name parameter, if passed.
In both of the defined routes, the function is called and the return value passed to logfmt.stringify(), which serializes the object to the logfmt format. This is in turn passed to console.log() for an easy way of logging the information.
In more sophisticated setups, you could write to log files or remote logging services, such as Papertrail or Splunk. If you were to run the above code and make a request to either / or to /matthew, the following would be output to the console from which the process was initiated:
baseUrl="/" hostname=localhost protocol=http baseUrl="/" hostname=localhost protocol=http name=matthew
Now, in more production applications, there’d likely be much more sophisticated instrumentation. This could include details about the logged in user, the dispatched route, as well as a variety of other information, about the current application’s executing state. But for the purposes of a simple example, the above code works well.
How to Parse Logs
Now that we’ve looked at generating logs, how do you parse them? Parsing comes down to what you’ve logged, so it’s hard to provide a definitive, codified answer as to how to parse them.
However, there are a couple of tools available, called hutils. They’re developed at Heroku, and they help make the process simpler. There are four tools available in the set:
- lcut: Extracts values from a logfmt trace based on some field name
- lfmt: Prettifies logfmt lines as they emerge from a stream and highlights their key sections
- ltap: Accesses messages from popular log providers in a consistent way so that it can easily be parsed by other utilities that operate on logfmt traces.
- lviz: Helps to visualize logfmt output by building a tree out of some set of data by combining common sets of key/value pairs into shared parent nodes
Let’s have a look at lcut and lviz, using data logged from the earlier application. Let’s assume that the application, instead of logging to the console, was logging to a file, located at /project/root/log/log.file. Also, let’s assume that that file contained the following records:
baseUrl="/" route=getName hostname=localhost protocol=http name=matthew baseUrl="/" route=getName hostname=localhost protocol=http name=james baseUrl="/" route=getName hostname=localhost protocol=http name=peter baseUrl="/" route=getName hostname=localhost protocol=http name=roger baseUrl="/" route=getName hostname=localhost protocol=http name=albert baseUrl="/" route=getName hostname=localhost protocol=http name=nicholas baseUrl="/" route=getName hostname=localhost protocol=http name=angela baseUrl="/" route=getName hostname=localhost protocol=http name=robert
lviz
We’ll start off with lviz. I’ll cat the output of the log file to lviz by using the command cat log.file | lviz. You can see the result in the screenshot below:
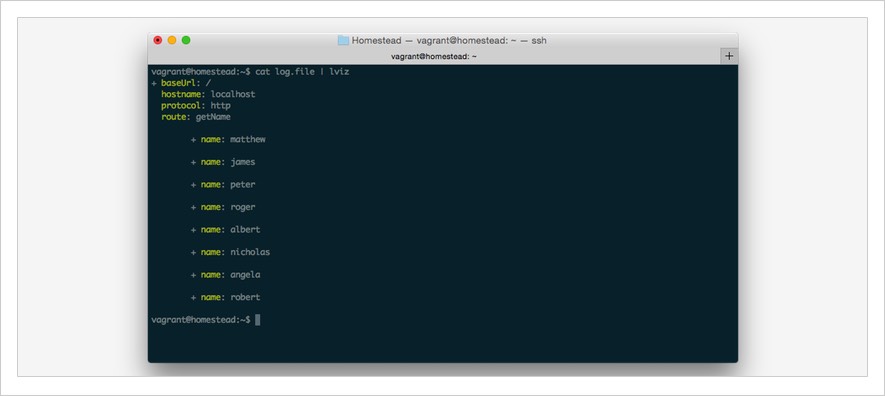
You can see that each of the elements which are the same, have been output only once. However, all of the differences (e.g., the name property) have been output in a subordinate tree format. This makes it pretty simple to get a quick grasp on the information at hand.
lcut
Now let’s have a look at lcut. In this scenario, I just want to extract several of the fields from the logged information. Specifically, I want to get the route and the name.
To do so, again, I’ll cat the contents of the log file to lcut and specify the columns which I want to extract: route and name. I do this with the following command: cat log.file | lcut route name. You can check out the result in the screenshot below:
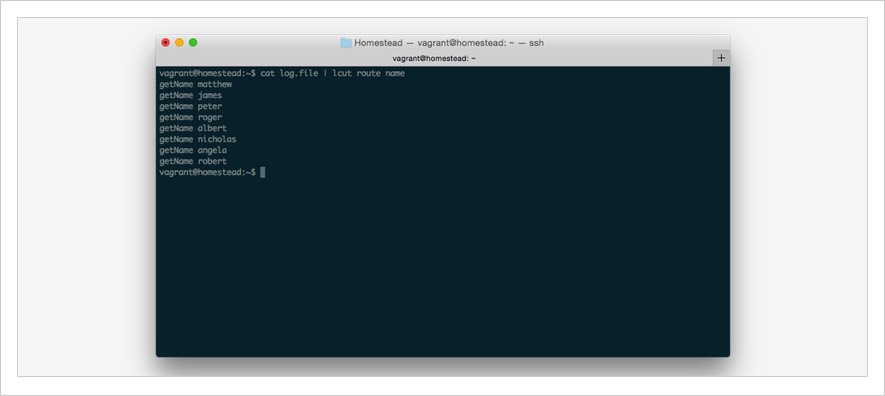
Here, you can see, listed in the output, the two columns requested. This could then be piped to any number of other commands to perform further analysis on the data extracted.
What Libraries Are Available
Logfmt isn’t that old, but there are already a number of language bindings available:
- Node.js
- Go
- Python
- Ruby
- Elixir
- Rust
- Haskell
- Erlang
- Clojure
- Dart
- Java
- and a number of language frameworks, like Angular.js
Over the coming months, I’d expect to see more language bindings coming available. Alternatively, you could implement it in your desired language of choice instead of waiting, if you feel so inclined.
What Services Are Available
While the format’s still relatively new, there are a number of services starting to make use of it. These include Splunk, Papertrail, and librato. There are also plugins available for Logstash and Maven.
Wrap Up
While logfmt isn’t revolutionary in nature, it’s definitely a step in the right direction for more universal, more manageable logging. If you’re stuck finding a logging format or a logging approach that works for your application, definitely consider the simplicity and universality of logfmt.
Already using it? What’s your experience been with it? Share your thoughts in the comments.
| Reference: | Logfmt: A Log Format That’s Easy To Read and Write from our WCG partner Florian Motlik at the Codeship Blog blog. |

This article is stolen. The original one is here : http://blog.codeship.com/logfmt-a-log-format-thats-easy-to-read-and-write/
Hello John,
We do NOT steal content. Codeship is our WCG (http://www.webcodegeeks.com/join-us/wcg/) partner, so they have given us permission to syndicate content from their blog.
Please do your homework before raising an accusation.
Byron
Then what about attributing it to Florian Motlik when the original author is Matthew Setter ? This is not how it’s supposed to work.
That’s not how this is presented. It looks like a straight scrape. Shady stuff.