This is the second of a three-part series on working with DynamoDB. The first article covered the basics of DynamoDB, such as creating tables, working with items along with batch operations, and conditional writes.
This post will focus on different ways you can query a table in DynamoDB and, more important, when to take advantage of which operation efficiently, including error handling and pagination.
In the first post, we created a users table that contains items with a user‘s information. Each user was identified by a unique email field, making email the ideal candidate for the Partition Key (or Hash Key). The Sort Key (or Range Key) of the Primary Key was intentionally kept blank.
Apart from the Primary Key, one Global Secondary Key was also created for the expected searching pattern of the users table. It’s intuitive that searching functionality will focus mainly on searching users based on their name and creation time, which makes the created_at field an ideal candidate for the Partition Key and the first_name field as the Sort Key.
Additionally, instead of normalizing Authentication Tokens and Addresses into separate tables, both pieces of information are kept in a users table.
Table Structure
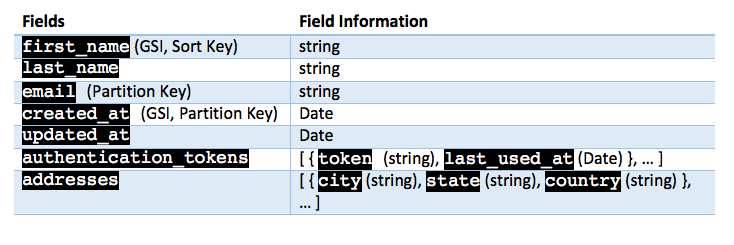
Create a users table in DynamoDB with the above structure if you haven’t already. Check out the first post in the series if you get stuck.
Querying in DynamoDB comes in two flavors: query operation and scan operation. Both operations have different use cases.
Query Operation
The query operation in DynamoDB is different from how queries are performed in relational databases due to its structure. You can query only Primary Key and Secondary Key attributes from a table in DynamoDB.
The query operation finds items based on Primary Key values. You can query any table or secondary index that has a composite Primary Key (a Partition Key and a Sort Key). – AWS DynamoDB
Sounds constraining, as you cannot just fetch records from a database table by any field you need. But that’s where you compromise flexibility in querying with speed and flexibility of data storage.
NoSQL databases must be designed by keeping data access patterns and application requirements in mind, whereas SQL databases are designed around the structure of data and normalization. This distinction will help you tremendously in designing databases in NoSQL.
Querying with a Primary Index
Suppose you want to authenticate a user with the authenticate token. You will first need to fetch a user with email and check if the token provided by the user matches one of the tokens in the authentication_tokens attribute.
# models/user.rb
...
def self.find_by_email(email)
if email
begin
query_params = {
table_name: table_name,
expression_attribute_names: {
'#hash_key_name' => 'email'
},
expression_attribute_values: {
':hash_key_val' => email
},
key_condition_expression: '#hash_key_name = :hash_key_val',
limit: 1
}
resp = $ddb.query(query_params)
# return first item if items matching key condition expression found
resp.items.try(:first)
rescue Aws::DynamoDB::Errors::ServiceError => e
puts e.message
nil
end
else
nil
end
end
...An interesting part in the #find_by_email method is the query_params hash. query_params can be broken down into three main parts:
table_name– The name of the table against which the query is being performed.expression_attribute_namesandexpression_attribute_values– These hold the alias of attribute names and attribute values respectively, which are to be used in query statement. By convention,expression_attribute_namesare prepended with#andexpression_attribute_valuesare prepended with:.key_condition_expression– An actual query statement containing an attribute name alias with values and operators. The operators allowed inkey_condition_expressionare=,>,<,>=,<=,BETWEEN, andbegins_with.
In every query, the Key condition expression must contain a Partition Key with a value and the equality operator = for that value. By this rule, all our queries will contain the #hash_key_name = :hash_key_val part. No operator other than = can be used with the Partition Key.
The Sort Key isn’t used in the above query, as specifying a Sort Key is optional in a query statement. The Sort Key is primarily used to narrow down results for items with a particular hash key.
The query operation always returns a result set in the items key, which can be empty if no record is found matching the criteria specified by the query. Also, the items in a result are in ascending order by default.
To get items in descending order, you need to pass
scan_index_forwardoption as false in a query hash.
One other part that’s omitted in the above query is filter_expression. It filters out items from a result set that does not match filter_expression. filter_expression can only be applied to attributes other than Partition Key or Sort Key attributes. filter_expression is applied after a query finishes, but before results are returned.
Querying with Secondary Index
By default, a query operation is performed with Primary Index attributes. To perform querying with a Secondary Index, you need to specify the name of a Secondary Index with index_name key in the query hash. All other rules remain the same as when querying with a Primary Index.
Suppose you now need to search users registered on a particular day and whose first name start with jon. A SQL equivalent query would be:
select users.* where users.created_at = ' xxx ' and users.first_name = 'jon%'
A Global Secondary Index with the name created_at_first_name_index created while the table is created can be used to to perform this query.
# models/user.rb
def self.first_name_starts_with(name)
if name
begin
query_params = {
table_name: table_name,
index_name: 'created_at_first_name_index'
expression_attribute_names: {
'#hash_key_name' => 'created_at',
'#range_key_name' => 'first_name'
},
expression_attribute_values: {
':hash_key_val' => DateTime.current,
':range_key_val' => 'jon'
},
key_condition_expression: '#hash_key_name = :hash_key_val AND begins_with(#range_key_name, :range_key_val) '
}
$ddb.query(query_params).items
rescue Aws::DynamoDB::Errors::ServiceError => e
puts e.message
nil
end
else
nil
end
endThe above method is very similar to the #find_by_email method and returns the result of items matching users created today and whose name start with jon.
Since you need to access all users created on a certain date, avoid using the limit option. However, in most of the queries, you will want to limit the number of items returned. Otherwise, in certain situations, such queries will turn out to be very expensive, as read capacity units will be consumed if the size of the returned items is large. After read capacity units are consumed, your query operations will be throttled.
A query operation is used to create finder methods such as #find, #find_by, and class methods or scopes with query logic that fetches items from database to Rails models. Additionally, you will need to use filters and Local and Global Secondary Indexes to query efficiently.
Scan Operation
Similar to a query operation, a scan operation can be performed against a table with either a Primary or Secondary Index. But unlike a query operation, a scan operation returns all items from the table. A scan operation is useful when you need to access most of the items for a table and do not need to filter out a large amount of data.
A scan operation will read all the items from a table sequentially. It will consume read capacity for an index very quickly. AWS recommends limiting scan operations, otherwise read capacity units will be consumed very quickly and this will affect performance.
If you want to get all users whose name start with jon regardless of the date the users were created, a scan operation can be used.
# models/user.rb
def self.all_users_with_first_name_as(name)
if name
begin
scan_params = {
table_name: table_name,
expression_attribute_names: {
'#range_key_name' => 'first_name'
},
expression_attribute_values: {
':range_key_val' => name
}
filter_expression: 'begins_with(#range_key_name, :range_key_val)'
}
$ddb.scan(scan_params).items
rescue Aws::DynamoDB::Errors::ServiceError => e
puts e.message
nil
end
else
nil
end
endInstead of a key condition expression, a filter expression is used to fetch users. table_name, expression_attribute_names, and expression_attribute_values are similar to a query operation. A filter expression can be used with a query operation in a similar manner.
Filter expressions slow down query response time if a large amount of data needs to be filtered. However, I prefer to use filter expressions instead of filtering out data in Ruby with custom logic, as working with large data is memory-consuming and slower.
Extending a Query and Scan Operation with Pagination
A query and scan operation returns a maximum 1 MB of data in a single operation. The result set contains the last_evaluated_key field. If more data is available for the operation, this key contains information about the last evaluated key. Otherwise, the key remains empty.
You need to check if the last_evaluated_key attribute is present, and construct the query again, setting the value of last_evaluated_key from response to exclusive_start_key of the query_params hash. This will tell DynamoDB to start returning items from the given exclusive_start_key, from where the last response returned.
This process needs to be continued until last_evaluated_key is empty.
This is essential, as you never want to return an incomplete response to a user. Besides, pagination is needed in both query and scan operations. So we will move actual querying to the #query_paginated method, which will be used by finder methods.
# models/user.rb
def self.query_paginated(query_params, operation_type = 'query')
raise Exception, "Invalid Operation Type, #{operation_type}" unless ['query', 'scan'].include?(operation_type)
items = []
begin
loop do
result = $ddb.public_send(operation_type, query_params)
items << result.items
items.flatten!
if results.last_evaluated_key.present?
query_params[:exclusive_start_key] = result.last_evaluated_key
else
break
end
end
return items.flatten
rescue Aws::DynamoDB::Errors::ServiceError => e
puts e.message
return []
end
end
def self.first_name_starts_with(name)
...
# replace $ddb.query(query_params).items with query_paginated method call as below
query_paginated(query_params, 'query')
...
end
def self.all_users_with_first_name_as(name)
...
# replace $ddb.scan(scan_params).items with query_paginated method call as below
query_paginated(scan_params, 'scan')
...
endRead Consistency for Query and Scan
DynamoDB replicates data across multiple availablility zones in the region to provide an inexpensive, low-latency network.
When your application writes data to a DynamoDB table and receives an HTTP 200 response (OK), all copies of the data are updated. The data will eventually be consistent across all storage locations, usually within one second or less. – AWS DynamoDB
Eventual consistent read
Performing an Eventual Read operation means the result might not reflect the result of a recently completed write operation.
Strongly consistent read
Performing a Strongly Consistent Read ensures you always receive recently updated data.
Capacity units with query and scan
Every read operation (query, scan, GetItem, BatchGetItem) consumes read capacity units. The capacity units determine how much you will be charged for a particular operation.
By defining your throughput capacity in advance, DynamoDB can reserve the necessary resources to meet the read and write activity your application requires, while ensuring consistent, low-latency performance. – AWS DynamoDB
If a query or scan operation is performed on a table or Local Secondary Index, read capacity units specified for that table are consumed. When an operation is performed on a Global Secondary Index, read capacity units specified for GSI are consumed.
By default, an Eventual Consistent Read is used in scan and query operations. You can specify that you want a Strongly Consistent Read by specifying consistent_read as true. A Strongly Consistent Read operation consumes twice the read capacity units as an Eventual Consistent Read.
Read capacity units allocated for a table and GSI are evenly spread across all partitions. A sudden burst in read requests for a particular item, or multiple items in the same partition, easily consumes capacity units for a given partition. This results in request throttling.
This is known as a Hot Key problem. A Partition Key must be selected in a way so as to avoid this kind of situation. This kind of sudden burst should also be avoided.
One way to avoid such a sudden burst is to request data in batches along with pagination. Instead of requesting 20_000 items in single request, it would be better to request the items in four requests of 5_000 items each. This situation will be explained in detail in the next article in this series.
Conclusion
This article explains how to work with query and scan operations and when to use which operation. Pagination is very different than SQL databases, and ensuring that you receive complete data is quite important.
It’s evident that tables in DynamoDB must be designed by keeping data access patterns and application requirements in mind. Chosen Primary Indexes and Secondary Indexes determine how flexibly you can query the data. The indexes also determine how capacity units will be consumed, which in turn affects cost.
Read the DynamoDB Developer Guide’s “Working with Queries” and “Working with Scan” section to understand about querying concepts in detail.
The next article will focus on the partitioning behavior of DynamoDB, as well as different strategies for choosing indexes.
| Reference: | Querying and Pagination with DynamoDB from our WCG partner Parth Modi at the Codeship Blog blog. |
